
Im ersten Teil habe ich beschrieben, wie ich das Docker Image von Apache Zeppelin um die Spark Version 2.4.0 erweitert und kurz getestet habe.
In diesem Teil werde ich einen eigenen Interpreter für PostgreSQL hinzufügen und eine erste Abfrage durchführen, um diesen zu testen. Danach wird noch die Konfiguration für den Spark Interpreter angepasst, damit dieser auch mit PostgreSQL arbeiten kann.
Um den neuen Interpreter hinzuzufügen, klicke ich auf das Drop-Down Menü, rechts im Zeppelin Header und wähle den Punkt Interpreter aus
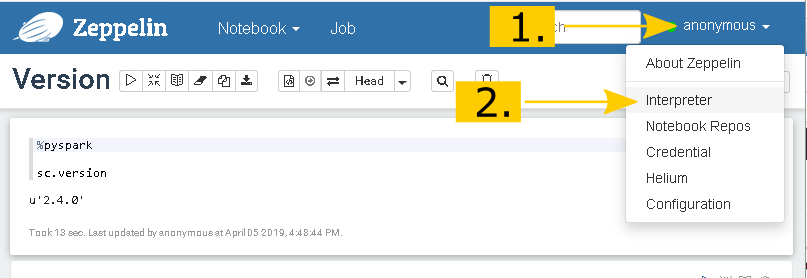
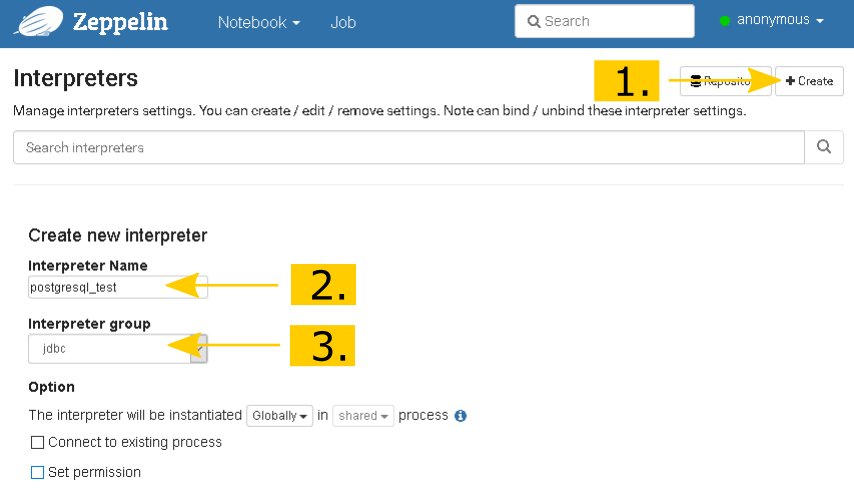
Mit Create wird die Seite zum Konfigurieren des neuen Interpreters geladen und unter Interpreter Name können wir unseren eigenen Wunschnamen vergeben. Da ich mich auf die Datenbank mit dem Namen Test auf dem PostgreSQL Server verbinden will, habe ich hier den Namen postgresql_test verwendet.
Zeppelin hat die Unterstützung für Java Database Connectivity (JDBC) ja bereits eingebaut. Daher können wir als Interpreter Group einfach jdbc auswählen und bekommen danach eine ensprechende Konfigurationsvorlage angezeigt.
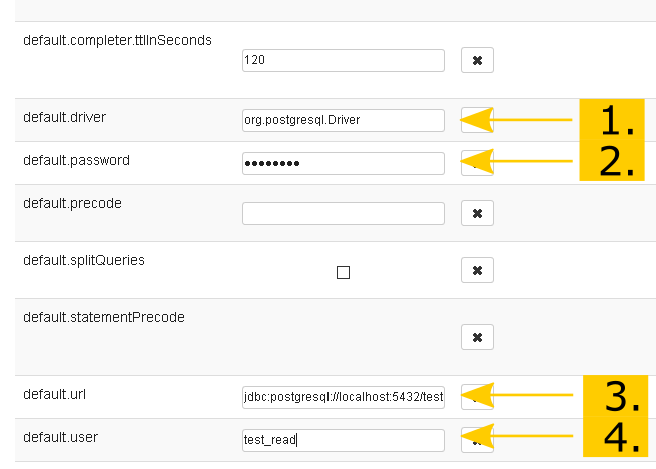
Glücklicherweise hat das Zeppelin Image den PostgreSQL Treiber schon vorinstalliert. Wir müssen also nur noch das Passwort, die URL und den Benutzer anpassen. Da dieser Interpreter sich direkt mit der Test Datenbank verbinden soll, füge ich der URL noch den Namen der Datenbank an. Die URL sieht also dann so aus:
jdbc:postgresql://localhost:5432/test
Zum Abschließen der Konfiguration wird jetzt noch gespeichert und danach können wir den neuen Interpreter auch gleich in einem neuen Notebook testen.
Dazu referenzieren wir in der ersten Zeile unseren Interpreter mit %postgresql_test und testen danach die Verbindung zur Datenbank, indem wir uns die Version anzeigen lassen.
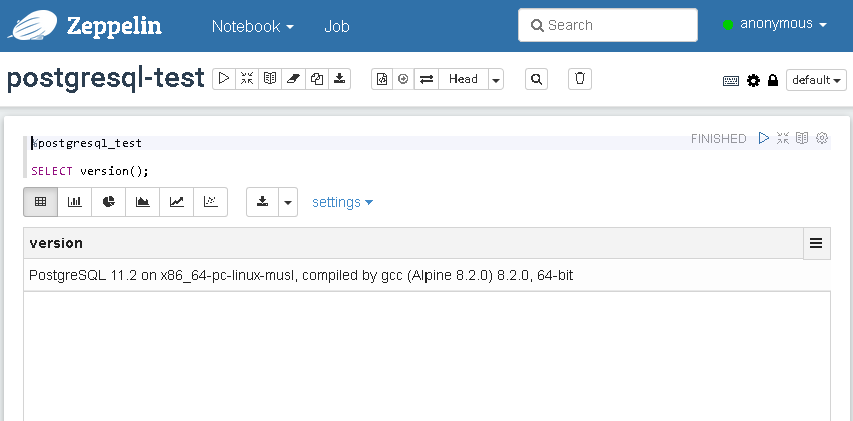
So wie es aussieht, hat alles funktioniert. Wunderbar!
1. June 2019
[…] wir in Teil 1 und Teil 2 bereits erfahren haben, wie wir Zeppelin direkt mit PostgreSQL benutzen können, widmet sich der […]