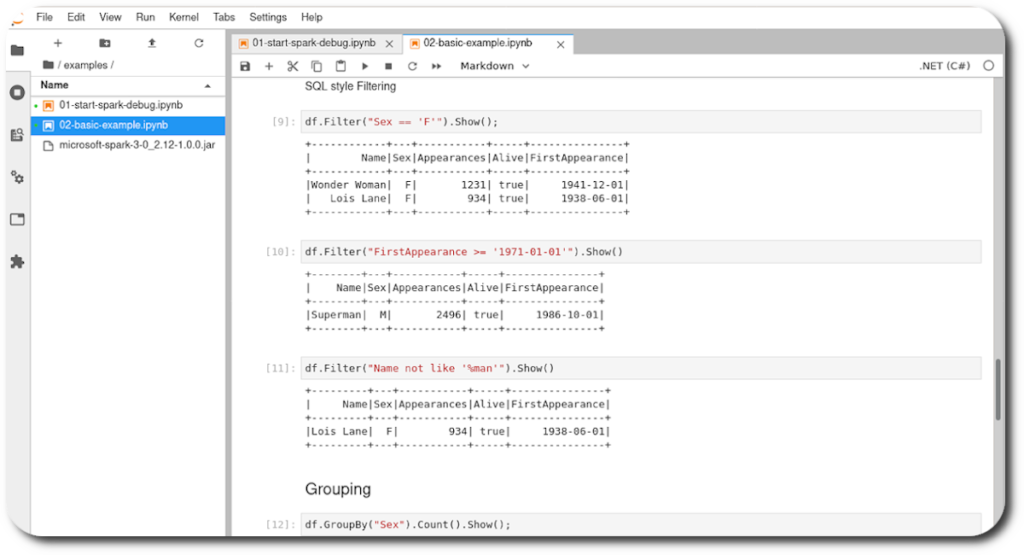
Microsoft just recently announced the release of .NET for Apache Spark 2.0.0.
It provides a couple of new features, like the support for the Apache Spark 3.1.0 APIs, for example.
Apache Spark 2.3.x support has now officially been dropped, however.
I have also updated my different docker images, so that you can try out all the different combinations of the supported Apache Spark versions along with the new .NET for Apache Spark 2.0.0 runtime.
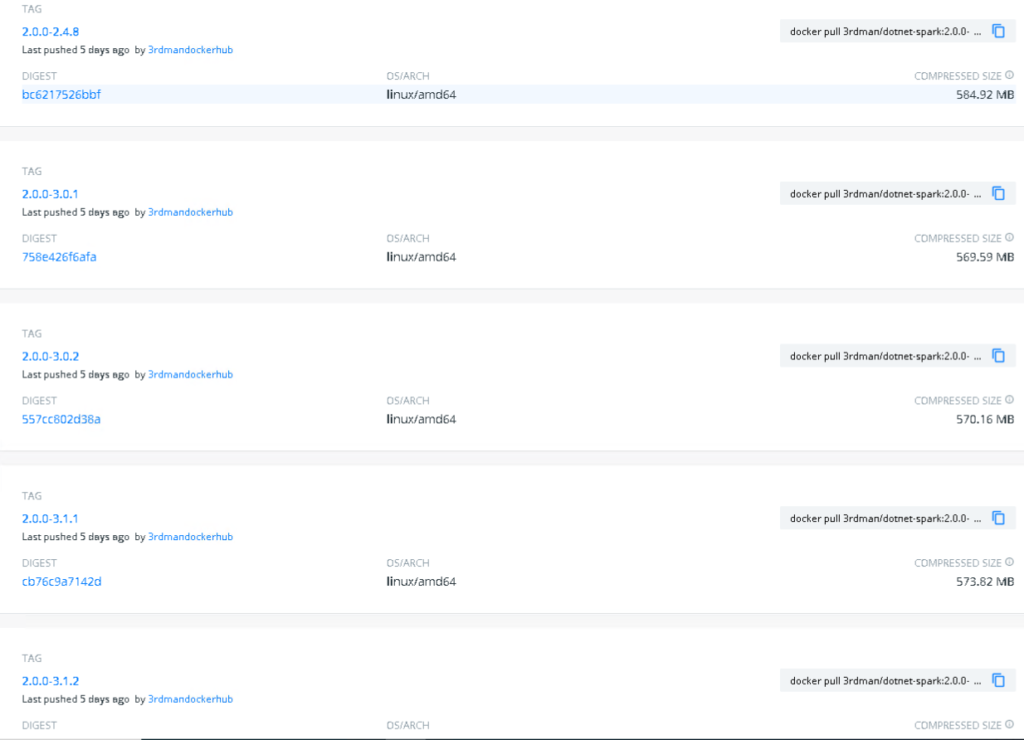
As you might be aware, there are actually 3 different kinds of docker images provided.
Interactive Jupyter Notebook
This image allows you … more