
In dieser kleinen Artikelserie beschreibe ich, wie man Apache Zeppelin mit dem PySpark Interpreter benutzen kann, um eine PostgreSQL Datenbank abzufragen.
Im ersten Teil werde ich das offizielle Docker Image von Apache Zeppelin 0.8.1 um Spark 2.4.0 erweitern. Danach geht es dann weiter mit der Konfiguration des Spark Interpreters um auf PostgreSQL zugreifen zu können. Anschließend werden wir uns mit PgBench eine Datenbank mit Test Daten generieren und zu guter Letzt werden wir diese Daten mit PySpark abfragen
Beginnen wir also mit dem Erweitern des Docker Images. Dazu habe ich folgendes Dockerfile verwendet:
FROM apache/zeppelin:0.8.1
ENV SPARK_VERSION=2.4.0
ENV HADOOP_VERSION=2.7
ENV SPARK_INSTALL_ROOT=/spark
ENV SPARK_HOME=${SPARK_INSTALL_ROOT}/spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}
RUN mkdir "${SPARK_INSTALL_ROOT}" && \
cd "${SPARK_INSTALL_ROOT}" && \
wget --show-progress --progress=bar:force:noscroll https://archive.apache.org/dist/spark/spark-${SPARK_VERSION}/spark-${S
PARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz && \
tar -xzf spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz && \
rm spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz
Wie ihr sehen könnt, wird die angegebene Spark-Version heruntergeladen, und im Verzeichnis /spark extrahiert.
Das Dockerfile habe ich im Verzeichnis zeppelin-spark gespeichert und kann damit, nachdem ich in das übergeordnete Verzeichnis gewechselt habe, nun das eigene Image bauen. Dazu führe ich folgenden Befehl aus:
docker build -t zeppelin-spark:0.8.1-2.4.0 zeppelin-spark
Dies erzeugt das Image mit dem Namen zeppelin-spark und dem Tag 0.8.1-2.4.0.
Nun kann ich mit dem Image einen neuen Container erzeugen und starten.
docker run -d -p 8088:8080 --rm -v ${PWD}/logs:/logs -v ${PWD}/notebook:/notebook -e ZEPPELIN_LOG_DIR='/logs' -e ZEPPELIN_NOTEBOOK_DIR='/notebook' -e SPARK_HOME='/spark/spark-2.4.0-bin-hadoop2.7' --name zeppelin-spark zeppelin-spark:0.8.1-2.4.0
Dabei wird Zeppelin von Port 8080 auf Port 8088 umgeleitet, und die Log- und Notebook-Dateien werden in den entsprechenden Unterverzeichnissen des momentanen Arbeitsverzeichnisses (${PWD}) gespeichert.
Wichtig ist auch, die Umgebungsvariable für SPARK_HOME richtig zu setzten.
Nun sollte der Container via docker ps -a anzeigt werden.

Mit dem Webbrowser kann ich mich jetzt auf Port 8088 verbinden, und ein neues Notebook erstellen.
Nachdem ich mit %pyspark den Python Spark Interpreter ausgewählt habe, kann ich die Spark Version mit sc.version abfragen
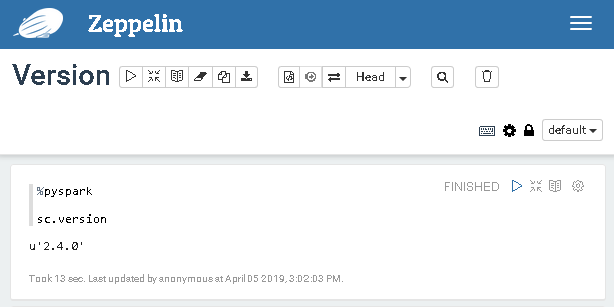
Die richtige Version wird angezeigt. Wunderbar!
17. June 2019
[…] wir in Teil 1 und Teil 2 bereits erfahren haben, wie wir Zeppelin direkt mit PostgreSQL benutzen können, widmet […]
17. June 2019
[…] ersten Teil habe ich beschrieben, wie ich das Docker Image von Apache Zeppelin um die Spark Version 2.4.0 […]