
Previously I have demonstrated how streaming data can be read and transformed in Apache Spark. This time I use Spark to persist that data in PostgreSQL.
Quick recap – Spark and JDBC
As mentioned in the post related to ActiveMQ, Spark and Bahir, Spark does not provide a JDBC sink out of the box. Therefore, I will have to use the foreach sink and implement an extension of the org.apache.spark.sql.ForeachWriter. It will take each individual data row and write it to PostgreSQL.
Preparing PostgreSQL

Even though I want to use PostgreSQL, I am actually going to use a TimescaleDB docker image.
But no worry. TimescaleDB is an extension of PostgreSQL and offers some great features that are especially useful for processing time series data. I plan to explore some of these features in the future. For more information about installing TimescaleDB under Docker, click here.
But no worry. TimescaleDB is an extension of PostgreSQL and offers some great features that are especially useful for processing time series data. I plan to investigate some of these features in the future, so I decided to use the TimescaleDB Docker image already. More information about installing TimescaleDB under Docker can be found here.
Looking at the data columns gives you an idea of which columns are needed in the database.
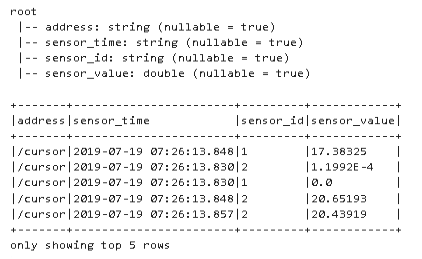
This leads me to the following create statement for the sensor_data table in the database named pipeline.
CREATE TABLE sensor_data( id BIGSERIAL PRIMARY KEY, sensor_time TIMESTAMP NOT NULL, sensor_id VARCHAR (50) NOT NULL, sensor_value REAL NOT NULL );
As you may have noticed, I will not save the address data. However, I have created an ID column that is automatically incremented and also acts as a primary key.
Spark to PostgreSQL – PostgreSqlSink
I have created the PostgreSqlSink class below, based on an example that I’ve found on the internet. I think it was this post on stackoverflow, or maybe this link.
%spark
import java.sql._
class PostgreSqlSink(url: String, user: String, pwd: String) extends org.apache.spark.sql.ForeachWriter[org.apache.spark.sql.Row] {
val driver = "org.postgresql.Driver"
var connection: java.sql.Connection = _
var statement: java.sql.PreparedStatement = _
val v_sql = "insert INTO sensor_data(sensor_time, sensor_id, sensor_value) values(to_timestamp(?,'YYYY-MM-DD HH24:MI:SS.MS'), ?, cast(? as real))"
def open(partitionId: Long, version: Long): Boolean = {
Class.forName(driver)
connection = java.sql.DriverManager.getConnection(url, user, pwd)
connection.setAutoCommit(false)
statement = connection.prepareStatement(v_sql)
true
}
def process(value: org.apache.spark.sql.Row): Unit = {
// ignoring value(0) as this is address
statement.setString(1, value(1).toString)
statement.setString(2, value(2).toString)
statement.setString(3, value(3).toString)
statement.executeUpdate()
}
def close(errorOrNull: Throwable): Unit = {
connection.commit()
connection.close
}
}
There are a couple of things worth mentioning:
val driver = "org.postgresql.Driver"
Sets the correct driver for the database.
val v_sql = "insert INTO sensor_data(sensor_time, sensor_id, sensor_value) values(to_timestamp(?,'YYYY-MM-DD HH24:MI:SS.MS'), ?, cast(? as real))"
Defines the insert statement and performs casting to match the data types of the sensor_data table. The question marks are the placeholders/parameters that are used in the process method.
def process(value: org.apache.spark.sql.Row): Unit = {
// ignoring value(0) as this is address
statement.setString(1, value(1).toString)
statement.setString(2, value(2).toString)
statement.setString(3, value(3).toString)
statement.executeUpdate()
}
By executing the paragraph in Zeppelin, I make this class available to the processing pipeline.
The result looks like this.
With the sink class defined, we now can look at how to use in the next zeppelin paragraph.
Spark to PostgreSQL – the final code
%spark
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.streaming.Trigger
// create a named session
val spark = SparkSession
.builder()
.appName("ReadMQTTStream")
.getOrCreate()
// read data from the OscStream topic
val mqttDf = spark.readStream
.format("org.apache.bahir.sql.streaming.mqtt.MQTTStreamSourceProvider")
.option("brokerUrl","tcp://192.168.10.159:1883")
.option("topic","OscStream")
.load()
// convert binary payload to string
val payloadDf = mqttDf.selectExpr("CAST(payload AS STRING)").as[String]
// split string into array of strings for each future column
val split_col = payloadDf.withColumn("payload", split(col("payload"), ";"))
// user regular expressions to extract the column data
val address = regexp_replace(split_col.col("payload").getItem(0), "\\[\\w+\\]:", "")
val sensor_time = regexp_replace(split_col.col("payload").getItem(1), "\\[\\w+\\]:", "")
val sensor_id = regexp_replace(split_col.col("payload").getItem(2), "\\[\\w+\\]:", "")
val sensor_value = regexp_replace(split_col.col("payload").getItem(3), "\\[\\w+\\]:", "")
// create the new columns with the extracted data,
// drop the original payload column and
// only get /cursor related data
val res = split_col
.withColumn("address", address)
.withColumn("sensor_time", sensor_time)
.withColumn("sensor_id", sensor_id)
.withColumn("sensor_value", sensor_value cast DoubleType)
.drop("payload")
.where("address = '/cursor'")
val url = "jdbc:postgresql://192.168.10.157:5432/pipeline"
val user = "pipeline"
val pw = "Ch4ng3Me!"
val jdbcWriter = new PostgreSqlSink(url,user,pw)
val writeData = res.writeStream
.foreach(jdbcWriter)
.trigger(Trigger.ProcessingTime("5 seconds"))
.outputMode("append")
.start()
print("Starting...")
writeData.awaitTermination(5)
After defining the JDBC URL, user and password for the database, a new instance of PostgreSqlSink is created as jdbcWriter.
This is then made available to the foreach sink.
As I don’t want to stress the database too much, I have also defined a trigger that will execute every 5 seconds. Once it fires, all the data that has been collected since the last time, will be written to the database.
Once executed, we can now get the status of our streaming query again.
%spark println(writeData.status) println(writeData.exception) println(writeData.lastProgress) writeData.explain()
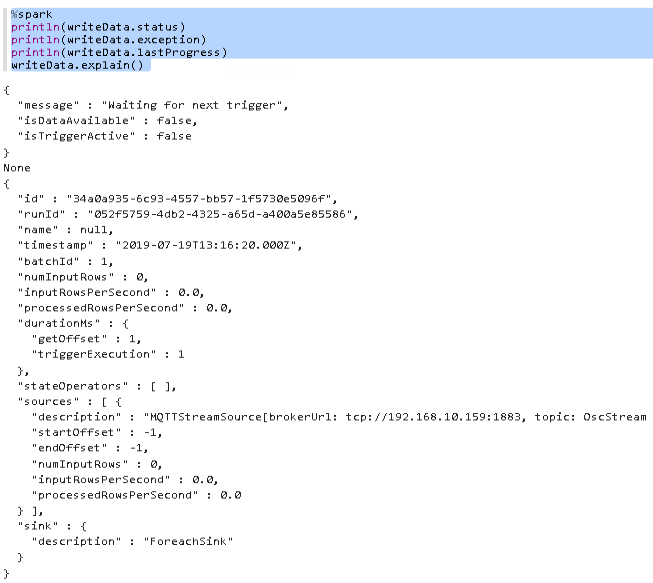
Excellent! The stream is waiting for input, but hasn’t received any data yet. So let’s start IanniX again and then look at the status again.
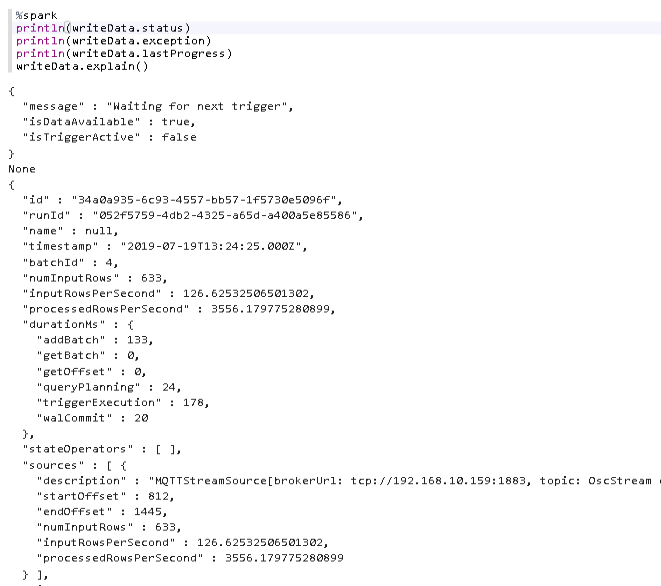
That looks exciting!
Let me check the if the data really has made it into the database.
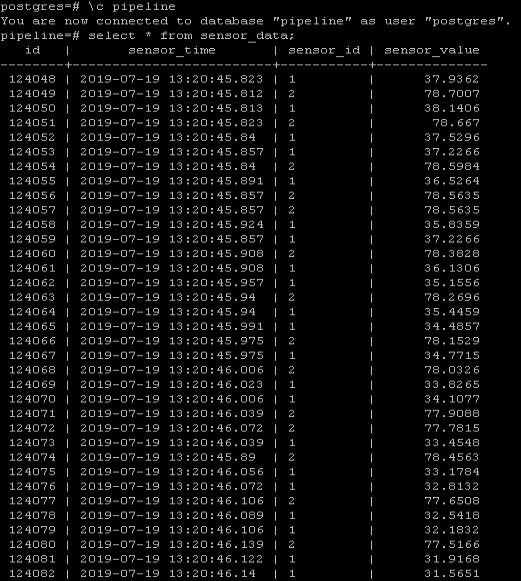
Success!!!
What’s left?
Spark to PostgreSQL? Done!
If you have a quick look back at the series overview, you’ll notice that we are getting closer to the end. The only thing that is left now, is to visualize the data that is written to the database in Grafana.
Looking forward to sharing the next part.
Cheers!
14. September 2019
[…] Part 5 – Spark to PostgreSQL […]
15. March 2020
[…] couple of months ago I’ve described how to transfer data from Apache Spark to PostgreSQL by creating a Spark ForeachWriter in […]