
Nachdem wir in Teil 1 und Teil 2 bereits erfahren haben, wie wir Zeppelin direkt mit PostgreSQL benutzen können, widmet sich der letzte Teil der Abfrage der Testdatenbank mit PySpark.
Ehe wir loslegen können, braucht unsere Datenbank erst einmal ein paar Testdaten. Da es in dieser Miniserie nicht um das Abfragen und Aufbereiten von Daten an sich geht, benutze ich für das schnelle Erzeugen von Daten einfach das Tool PgBench. Details dazu könnt ihr unter https://www.postgresql.org/docs/11/pgbench.html nachlesen.
Folgendes Kommando erzeugt dabei 100000 Datensätze in der Tabelle pgbench_accounts
pgbench -d -U testadmin -i test
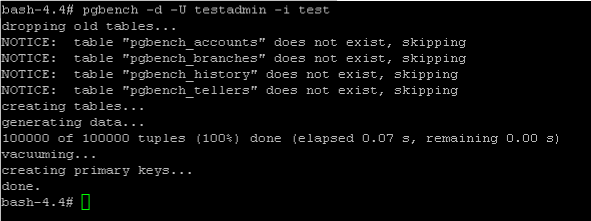
Nun können wir … more