

Having explained how to visually simulate sensor data and how to get it into ActiveMQ during the first two parts, it is now time to explore an initial setup that allows Apache Spark to read a data stream from ActiveMQ using Bahir.
Things to be aware of
Before we start, there are a couple of things you should be aware of, in case you want to follow along and try this out yourself.
Spark & Bahir version matching

As stated above, I would like to subscribe to an ActiveMQ topic with Apache Bahir to transfer the associated data into Spark. At the time of writing, the Bahir Spark Extensions are available in version 2.3.3.
As the version number of the Bahir Spark Extensions needs to match the Spark version, I have created myself a new Docker image that is based on the existing Apache Zeppelin Docker image.
Here is the content of the Dockerfile that I’ve used
FROM apache/zeppelin:0.8.1
ENV SPARK_VERSION=2.3.3
ENV HADOOP_VERSION=2.7
ENV SPARK_INSTALL_ROOT=/spark
ENV SPARK_HOME=${SPARK_INSTALL_ROOT}/spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}
RUN mkdir "${SPARK_INSTALL_ROOT}" && \
cd "${SPARK_INSTALL_ROOT}" && \
wget --show-progress --progress=bar:force:noscroll https://archive.apache.org/dist/spark/spark-${SPARK_VERSION}/spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz && \
tar -xzf spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz && \
rm spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz
Spark JDBC sink ?
Spark does not provide a JDBC sink out of the box and looking at the reply to a related request, it does not seem to be very likely that it will be added in the near future.
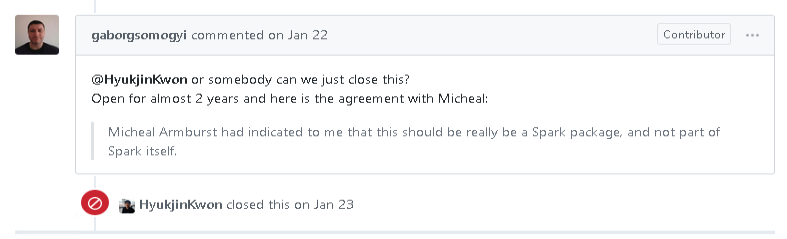
The good news is, that Apache Bahir will come to rescue here as well, as there seems to be support for a JDBC sink available in the next release.
Spark foreach sink …
The JDBC sink obviously will be quite handy, but for now, until the next version of Bahir has been released, I will have to utilize the foreach sink mechanism that is provided by Apache Spark.
Unfortunately Spark 2.3.3 does not support using the foreach sink for Python.
But that’s not a huge problem, as this is a great opportunity to play around with Scala a bit, as well.
Zeppelin Interpreter
As a last step to get things ready, I need to add the Bahir dependency to the Zeppelin Spark interpreter.
This is done via the Dependencies section at the bottom of the interpreter settings page.
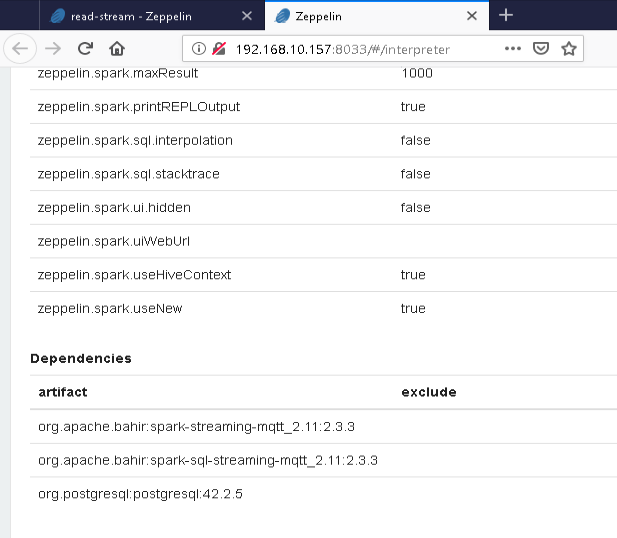
In case you prefer to copy & paste:
org.apache.bahir:spark-sql-streaming-mqtt_2.11:2.3.3
If you want to know more about Zeppelin, please have a look at some of my related posts, or have a look at the Apache Zeppelin homepage.
Putting things together
ActiveMQ, Spark & Bahir
Checking whether I actually can get any data from ActiveMQ, is the first thing to do.
The Scala code below creates a new spark session and is using Bahir’s MQTTStreamSourceProvider to connect to ActiveMQ via port 1883.
After that, the dataframe schema should be displayed to get a better idea about the data structure that I am receiving.
In order to actually look at the data, I need to write it to a supported Spark output sink. The memory sink is great for debugging purposes, as long as you don’t exceed your systems memory limit, of course.
awaitTermination is used to ensure that the stream is processed continuously until it is stopped, or an error is thrown. To make this work in Zeppelin, it is important to specify a timeout value, so that the UI won’t be blocked forever.
%spark
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
// create a named session
val spark = SparkSession
.builder()
.appName("ReadMQTTStream")
.getOrCreate()
// read data from the OscStream topic
val mqttDf = spark.readStream
.format("org.apache.bahir.sql.streaming.mqtt.MQTTStreamSourceProvider")
.option("brokerUrl","tcp://192.168.10.159:1883")
.option("topic","OscStream")
.load()
mqttDf.printSchema // print the schema of the received data
val memQuery = mqttDf.writeStream
.queryName("memQuery")
.format("memory")
.start()
println("Starting...")
memQuery.awaitTermination(5)
Executing this, gives me the following result
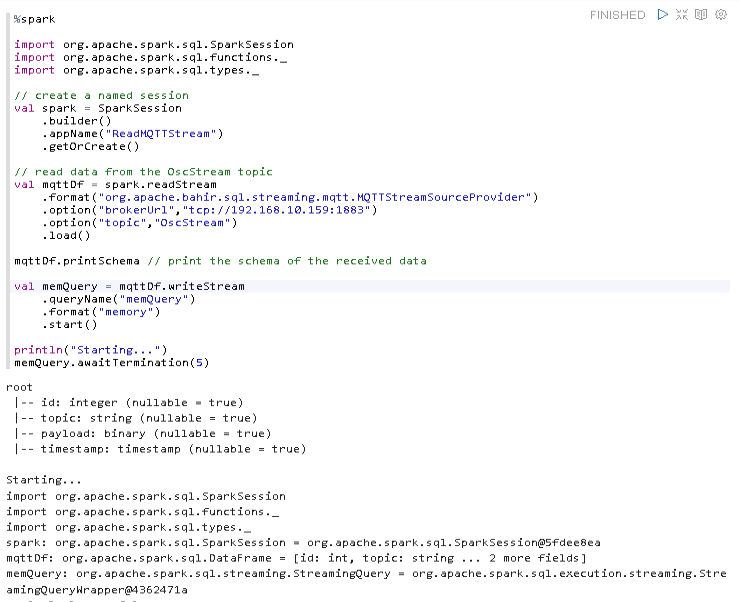
It is showing the correct schema, which tells me that it successfully connected to ActiveMQ.
Streaming Queries Monitoring & Management
Now let’s confirm that streaming is really up and running. The documentation explains all available management commands. I find the following most useful, to get a quick overview.
%spark
println("IsActive ..... => " + memQuery.isActive)
println("Status ....... => " + memQuery.status)
println("Last exception => " + memQuery.exception)
println("Last progress => " + memQuery.lastProgress)
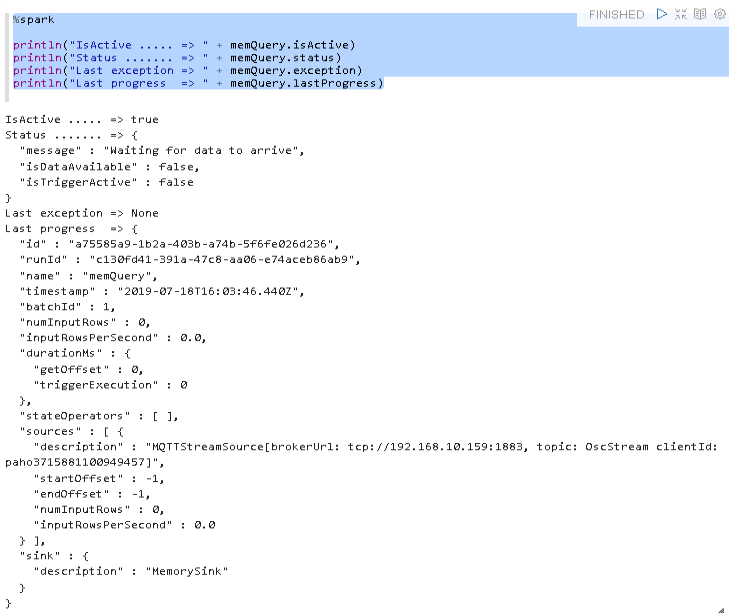
Looks like this reveals some use information. For example:
- The stream is active
- It is not processing any data at the moment, since I haven’t started IanniX yet
- No exceptions so far. Great!
Knowing how I can spin up streaming is great, but I also want to be able to stop and reset the query, so that I can reuse it as needed.
Here are the commands that allow me to do that:
%spark // stop streaming to the memory sink memQuery.stop() // reset any terminated streaming queries spark.streams.resetTerminated()
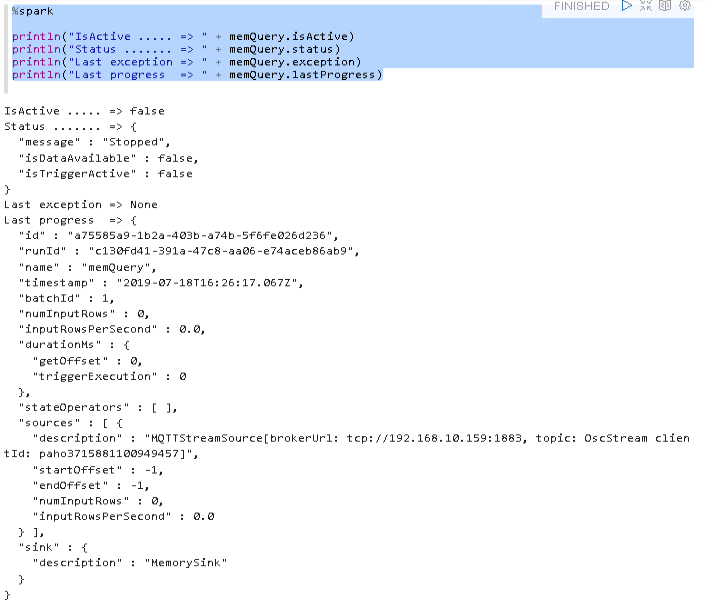
Querying the status of the stream now reflects that.
IsActive is false and the status message is set to Stopped.
Roundup & Outlook
In this part I have shown how to set the foundation for getting data from ActiveMQ into Spark using Bahir.
In the next part I will continue using the Memory Sink to support the transformation of the received data into the destination format that will be written to the database.
That is it for now. Thanks for reading and hopefully you have found this useful.
22. July 2019
[…] Part 3 - ActiveMQ, Spark & Bahir […]
9. August 2019
[…] far, we know how to get our streaming data from ActiveMQ into Spark by using Bahir. On this basis, it is now time to implement the data transformation required to get to the desired […]