
Nachdem wir in Teil 1 und Teil 2 bereits erfahren haben, wie wir Zeppelin direkt mit PostgreSQL benutzen können, widmet sich der letzte Teil der Abfrage der Testdatenbank mit PySpark.
Ehe wir loslegen können, braucht unsere Datenbank erst einmal ein paar Testdaten. Da es in dieser Miniserie nicht um das Abfragen und Aufbereiten von Daten an sich geht, benutze ich für das schnelle Erzeugen von Daten einfach das Tool PgBench. Details dazu könnt ihr unter https://www.postgresql.org/docs/11/pgbench.html nachlesen.
Folgendes Kommando erzeugt dabei 100000 Datensätze in der Tabelle pgbench_accounts
pgbench -d -U testadmin -i test
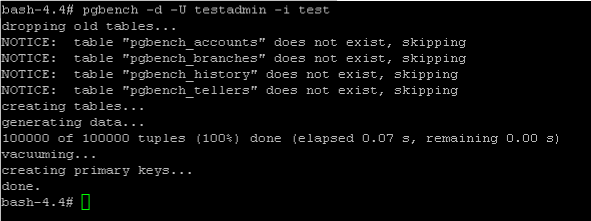
Nun können wir wieder unser Notebook verwenden, um die Anzahl von 100000 Datensätzen zu bestätigen.

Auch der Inhalt der einzelnen Datensätze lässt sich anzeigen.
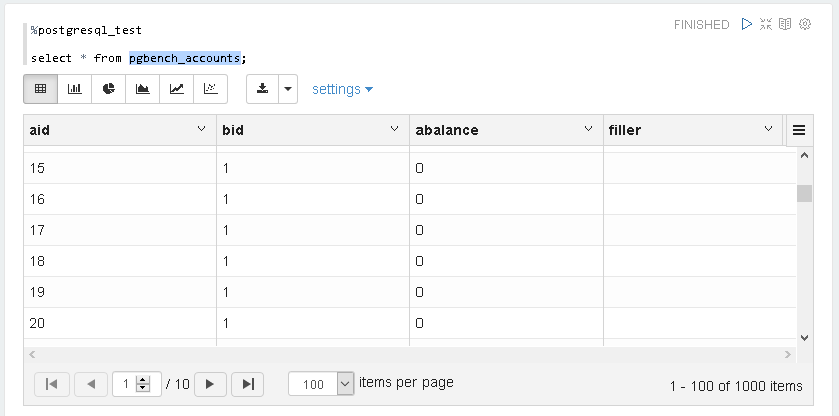
Die Datensätze sind also vorhanden und wir können sie mit unserem postgresql_test Interpreter auch direkt via JDBC abfragen. Wie machen wir das aber nun mit PySpark?
Zunächst müssen wir im Zeppelin Notebook den PySpark Interpreter einbinden. Dies geschieht mit %pyspark.
Danach wollen wir via sqlContext.read ein Verbindung zur PostgreSQL Datenbank “test” aufbauen und uns anschließend mit printSchema die Tabellenstruktur ansehen.
Leider erzeugt dies aber einen Fehler:
java.sql.SQLException: No suitable driver
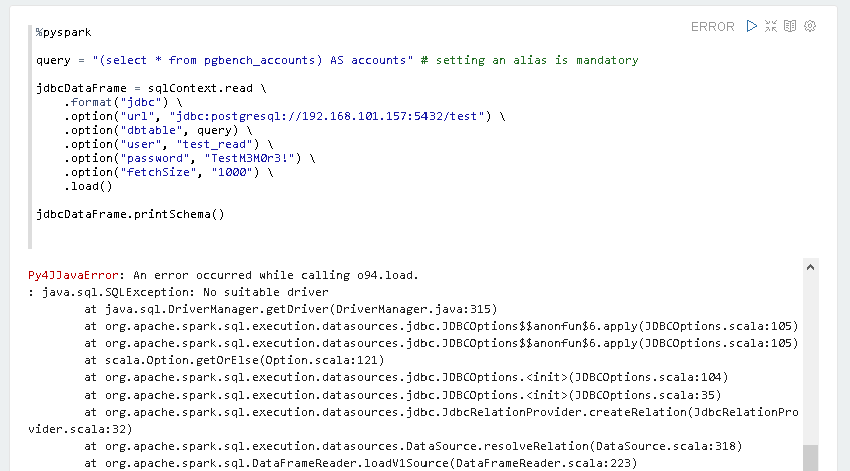
Dies mag zunächst sehr verwunderlich erscheinen, da wir ja gerade noch auf die Datenbank zugegriffen haben. Allerdings handelt es sich ja bei pyspark bzw. spark um einen anderen Interpreter, der nichts mit unserem, auf JDBC basierten Interpreter zu tun hat, und daher separat konfiguriert werden muss.
Glücklicherweise kann aber der PostgreSQL JDBC Treiber für Spark automatisch als Maven Artifact geladen werden. Die Definition für ein Artifact kann in dem Maven Glossar unter http://maven.apache.org/glossary.html#Artifact nachgelesen werden

Wie im Screenshot oben ersichtlich ist, wird ein Artifact durch folgende drei Elemente identifiziert.
- group id
- artifact id
- version
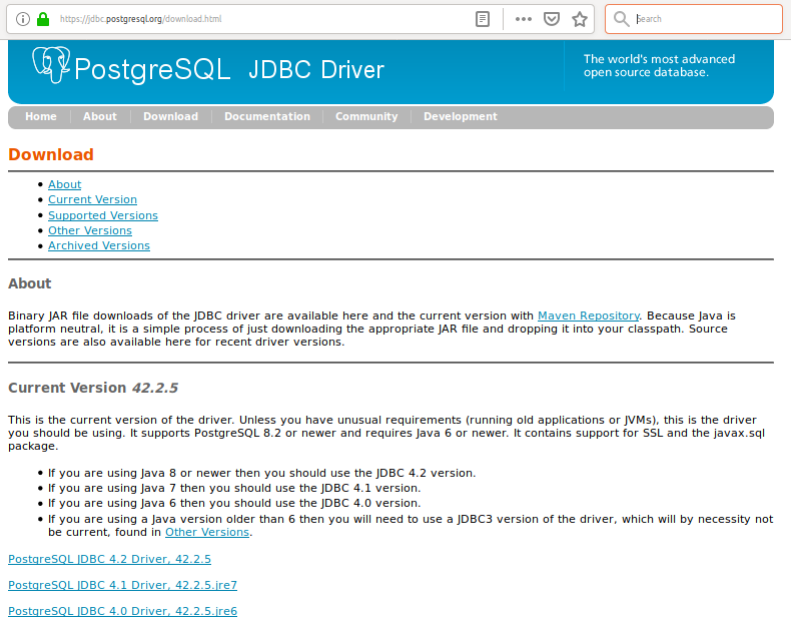
Für meinen Test will ich die momentan aktuellste Version des PostgreSQL JDBC Treibers installieren. Auf der Download-Seite von jdbc.postgresql.org ist die Versionsnummer ersichtlich.
Auf MVNRepository.com kann man sich die verfügbaren Artefakte für PostgreSQL unter https://mvnrepository.com/artifact/org.postgresql/postgresql anzeigen lassen.
Für die Version 42.2.5. sieht das z.B. so aus:
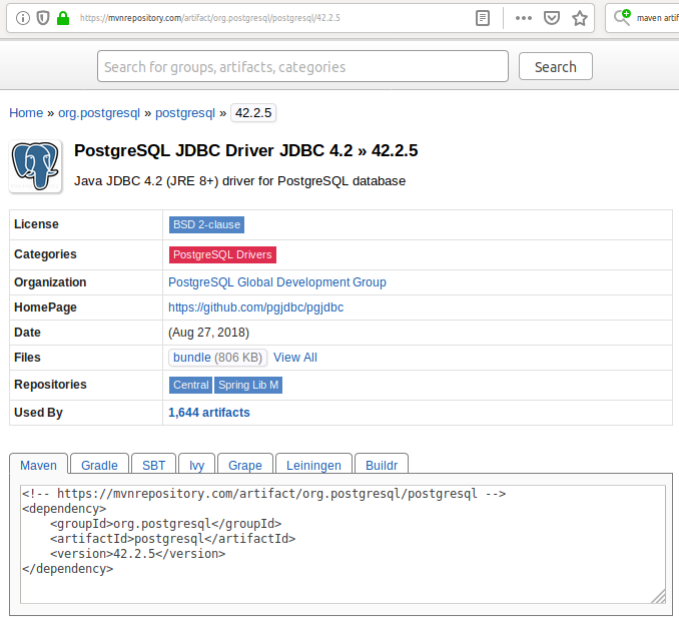
Die von unser benötigten Informationen sind also
Group Id: org.postgresql
Artifact Id: postgresql
Version: 42.2.5
Und wir können dies nun, durch Doppelpunkt getrennt, in das Artifact-Feld für die Spark Interpreter Einstellungen eintragen.
org.postgresql:postgresql:42.2.5

Nachdem die Einstellungen gespeichert wurden, können wir den Zeppelin Paragrafen nochmals ausführen.
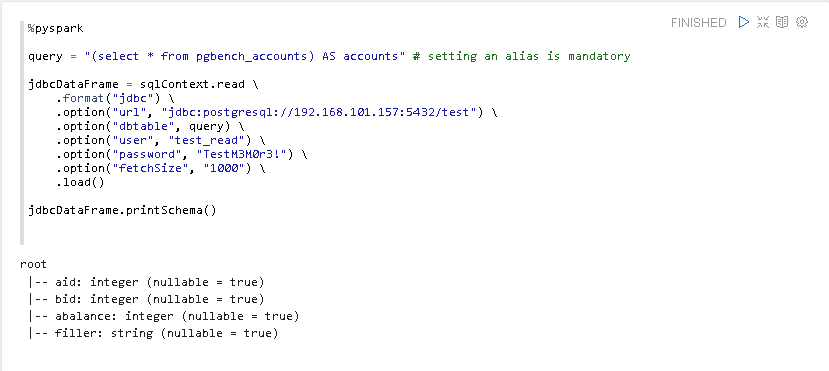
Und wie erhofft, wird dieses mal die Tabellenstruktur angezeigt.
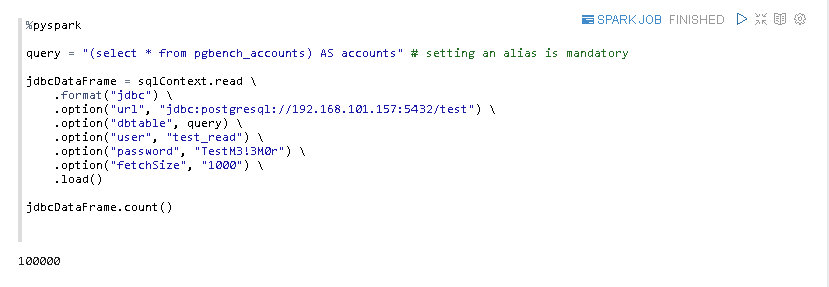
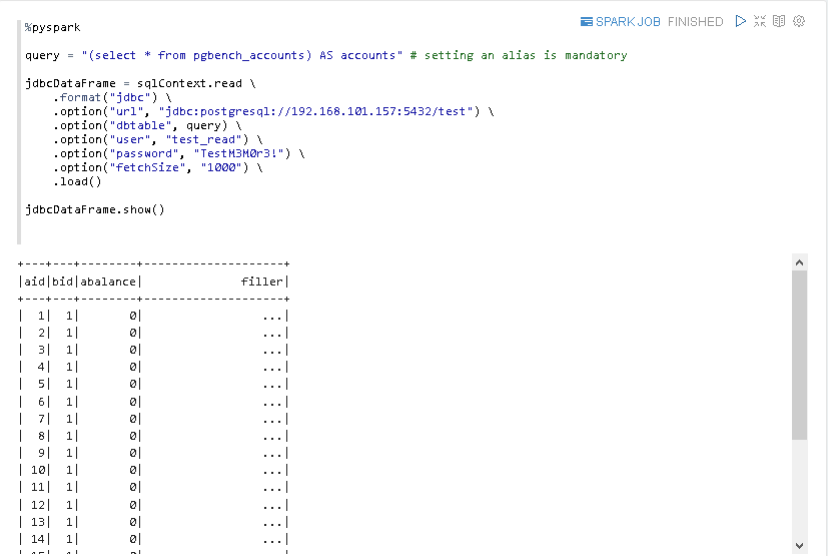
Auch die Anzahl und der Inhalt der ersten 20 Datensätze werden angezeigt.
Damit sind wir am Ende dieser kleinen Miniserie zum Thema “Apache Zeppelin mit PySpark und PostgreSQL benutzen” angelangt und ich hoffe, es waren ein paar nützliche Informationen für Euch dabei.
So long and cheers!