
So far, we know how to get our streaming data from ActiveMQ into Spark by using Bahir. On this basis, it is now time to implement the data transformation required to get to the desired output format.
Extract
As a quick reminder, here is the Scala code that I have used so far to retrieve the data from ActiveMQ and write it to a memory sink.
%spark
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
// create a named session
val spark = SparkSession
.builder()
.appName("ReadMQTTStream")
.getOrCreate()
// read data from the OscStream topic
val mqttDf = spark.readStream
.format("org.apache.bahir.sql.streaming.mqtt.MQTTStreamSourceProvider")
.option("brokerUrl","tcp://192.168.10.159:1883")
.option("topic","OscStream")
.load()
mqttDf.printSchema // print the schema of the received data
val memQuery = mqttDf.writeStream
.queryName("memQuery")
.format("memory")
.start()
println("Starting...")
memQuery.awaitTermination(5)
In the last article, I have just verified the connection to ActiveMQ, but this time I start up IanniX and submit some test data, after I executed the stream processing.
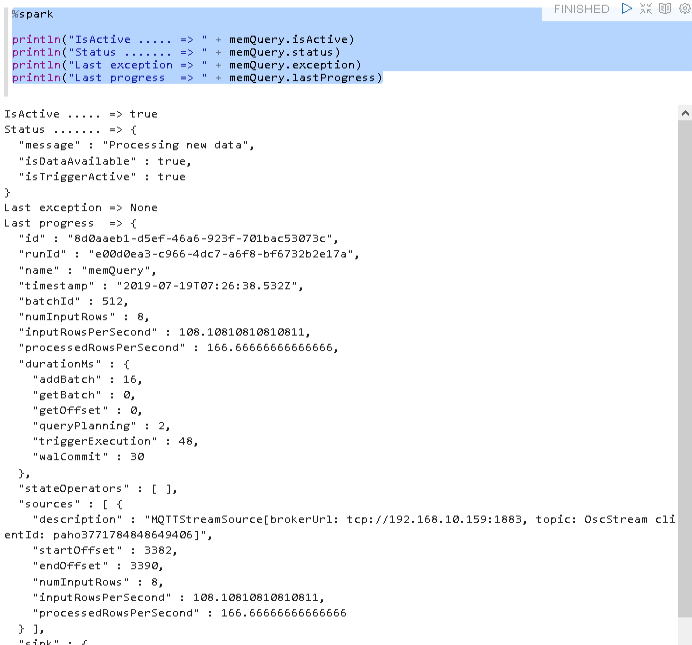
Checking the status of our streaming query now indeed shows that we are processing new data.
Very good. But how does the data actually look like?
To figure that out, I execute the following command in a new Zeppelin paragraph.
%spark
val raw = spark.sql("select * from memQuery")
raw.printSchema
println(raw.count())
raw.show(5)
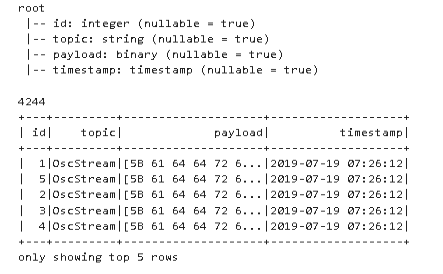
And this is the result:
Let’s compare this with the data that is published to ActiveMQ via OSC2ActiveMQ using the highest verbosity level

What we get is the sensor timestamp at index 0, the sensor id at index 1 and the sensor value at index 2. All of this is submitted as one message per data set and ends up in the payload column in Spark, in some binary format.
Transform
As our data is not provided as a plain text string, this needs to be the first step in our transformation pipeline.
Luckily enough, the Bahir documentation provides an example of how this can be accomplished.

Using this method additionally drops any other column as well, which is exactly what I want.
So let’s apply this to our query data.
%spark
val raw = spark.sql("select * from memQuery")
val payloadDf = raw.selectExpr("CAST(payload AS STRING)").as[String]
payloadDf.printSchema
payloadDf.show(5, false)
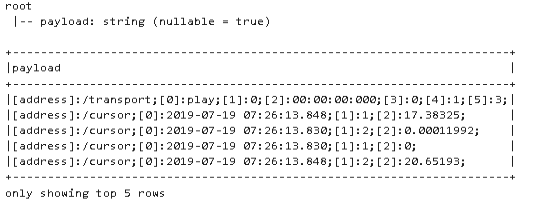
And what we get is:
Great stuff!
As we can see now, all the data is stored in one string that is separated by a semicolon. Therefore, I need to split this up into multiple columns as a next step.
%spark
val raw = spark.sql("select * from memQuery")
val payloadDf = raw.selectExpr("CAST(payload AS STRING)").as[String]
val split_col = payloadDf.withColumn("payload", split(col("payload"), ";"))
split_col.printSchema
split_col.show(5, false)
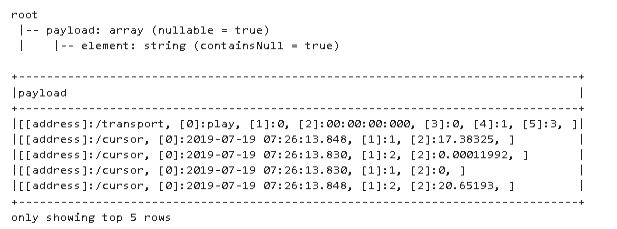
The output of printSchema now shows that the string was successfully converted to a string of arrays. Now, all that is left is to turn each element of the array into its own column.
Since my days back, when I was working with Perl, I am a big fan of regular expressions. So here is the new code making use of them in Scala.
%spark
val raw = spark.sql("select * from memQuery")
val payloadDf = raw.selectExpr("CAST(payload AS STRING)").as[String]
val split_col = payloadDf.withColumn("payload", split(col("payload"), ";"))
val address = regexp_replace(split_col.col("payload").getItem(0), "\\[\\w+\\]:", "")
val sensor_time = regexp_replace(split_col.col("payload").getItem(1), "\\[\\w+\\]:", "")
val sensor_id = regexp_replace(split_col.col("payload").getItem(2), "\\[\\w+\\]:", "")
val sensor_value = regexp_replace(split_col.col("payload").getItem(3), "\\[\\w+\\]:", "")
val res = split_col
.withColumn("address", address)
.withColumn("sensor_time", sensor_time)
.withColumn("sensor_id", sensor_id)
.withColumn("sensor_value", sensor_value cast DoubleType)
res.printSchema
res.show(5, false)
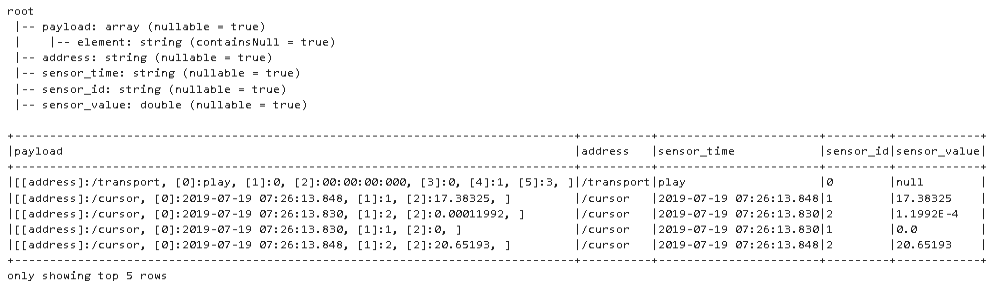
Almost there. Only two more things that I want to do.
1. Drop the payload column
2. Filter out data that doesn’t have “/cursor” in the address field.
So here is the final transformation code
%spark
val raw = spark.sql("select * from memQuery")
val payloadDf = raw.selectExpr("CAST(payload AS STRING)").as[String]
val split_col = payloadDf.withColumn("payload", split(col("payload"), ";"))
val address = regexp_replace(split_col.col("payload").getItem(0), "\\[\\w+\\]:", "")
val sensor_time = regexp_replace(split_col.col("payload").getItem(1), "\\[\\w+\\]:", "")
val sensor_id = regexp_replace(split_col.col("payload").getItem(2), "\\[\\w+\\]:", "")
val sensor_value = regexp_replace(split_col.col("payload").getItem(3), "\\[\\w+\\]:", "")
val res = split_col
.withColumn("address", address)
.withColumn("sensor_time", sensor_time)
.withColumn("sensor_id", sensor_id)
.withColumn("sensor_value", sensor_value cast DoubleType)
.drop("payload")
.where("address = '/cursor'")
res.printSchema
res.show(5, false)
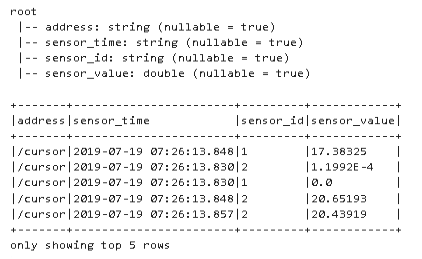
Exactly what I wanted. Great!
What’s next
We successfully used some of Spark’s data transformation capability, and the built in memory sink, to get the data in a state that can be used for further processing.
Next time I will show how persist the transformed data in a database.
Thanks again for your time and hope you stop by again soon!
9. August 2019
[…] Part 4 – Data transformation […]
3. September 2019
[…] I have demonstrated how streaming data can be read and transformed in Apache Spark. This time I use Spark to persist that data in […]
14. September 2019
[…] Data transformation […]