

Overview
My last article explained, how a .NET for Apache Spark project can be debugged in Visual Studio 2019 under Windows. I have also mentioned some limitation at the end of the article.
In this article I will extend the project a bit and demonstrate the aforementioned limitation using version 0.8.0 of my docker image for .NET for Apache Spark.
Furthermore, I will show a possible workaround that can be used, if you are running Docker and Visual Studio Code under Linux (Ubuntu 18.04).
The extended application
In order to demonstrate the issue, I have added some additional code to the HelloUdf project.
Below is the extended code, with the new bits highlighted.
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.Spark.Sql;
using static Microsoft.Spark.Sql.Functions;
namespace HelloUdf
{
class Program
{
static void Main(string[] args)
{
// create the spark session
SparkSession spark = SparkSession.Builder().GetOrCreate();
// create a dataframe from the json file
DataFrame df = spark.Read().Json("coordinates.json");
// show the original content
df.Show();
// create a user defined function that will split the data on ';'
Func<Column, Column> udfArray = Udf<string, string[]>((str) => SplitMethod(str));
// perform the split and add a new column name "coordinateArray" to store the string array of the split data
df = df.WithColumn("coordinateArray", udfArray(df["coordinate"]));
// display the original column "coordinate" along with the added column "coordinateArray"
df.Show();
// get the two items of the "coordinateArray" and put them in individual columns
Column colLatitude = df.Col("coordinateArray").GetItem(0);
Column colLongitude = df.Col("coordinateArray").GetItem(1);
// add the two new columns to the dataframe and drop the other two columns that are no longer needed
df = df
.WithColumn("latitude", colLatitude)
.WithColumn("longitude", colLongitude)
.Drop("coordinate")
.Drop("coordinateArray");
// now there should only be two columns named "latitude" and "longitude"
df.Show();
// collect the result from spark, ...
List<Row> rows = df.Collect().ToList();
// ... dispose the spark sessions ...
spark.Dispose();
// ... and do direct C# processing outside of spark
foreach (Row row in rows)
{
object[] rowValues = row.Values;
string latitude = rowValues[0].ToString();
string longitude = rowValues[1].ToString();
Console.WriteLine($"latitude: {latitude}, longitude:{longitude}");
}
}
// The method that is used by Udf
private static string[] SplitMethod(string stringToSplit)
{
Console.WriteLine($"\tsplitting: {stringToSplit}");
return stringToSplit.Split(';');
}
}
}
The coordinates.json file is the same as the one that I have used previously.
Preparing Visual Studio Code and the project
I have put the project under DEV/HelloUdf in my $HOME directory.
To bring up Visual Studio Code, I just use the following command in ~/DEV
code HelloUdf
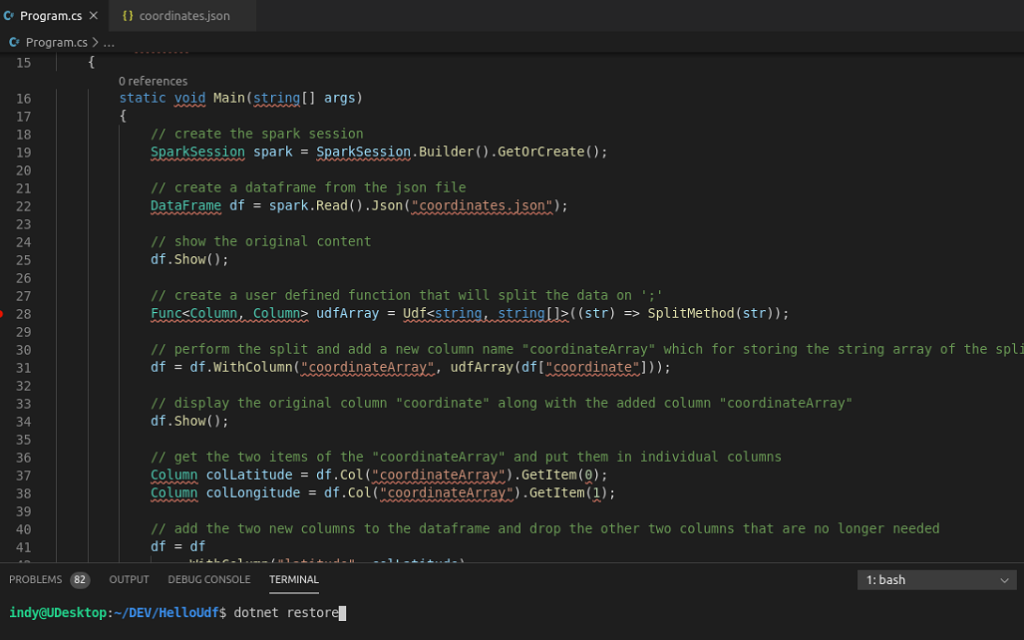
Initially you might see a lot of errors/warnings in the editor. That is, because Visual Studio Code cannot find the required packages. Fix that by going to the TERMINAL tab at the bottom and then type the following command in the bash shell.
dotnet restore
The highlighted errors should have disappeared now.
Before firing up a dotnet-spark container, I would like to recommend installing the Docker extension for Visual Studio Code. I am using it to view the container logs with VSC for example.
Another useful thing might be to disable the verbose logging of symbol/module load activities for better readability. See the “logging” configuration of the launch.json file below.
{
// Use IntelliSense to find out which attributes exist for C# debugging
// Use hover for the description of the existing attributes
// For further information visit https://github.com/OmniSharp/omnisharp-vscode/blob/master/debugger-launchjson.md
"version": "0.2.0",
"configurations": [
{
"name": ".NET Core Launch (console)",
"type": "coreclr",
"request": "launch",
"preLaunchTask": "build",
// If you have changed target frameworks, make sure to update the program path.
"program": "${workspaceFolder}/bin/Debug/netcoreapp3.1/HelloUdf.dll",
"args": [],
"cwd": "${workspaceFolder}",
// For more information about the 'console' field, see https://aka.ms/VSCode-CS-LaunchJson-Console
"console": "internalConsole",
"stopAtEntry": false,
"logging": {
"moduleLoad": false
}
},
{
"name": ".NET Core Attach",
"type": "coreclr",
"request": "attach",
"processId": "${command:pickProcess}"
}
]
}
As last preparation step, I am going to ensure that the “coordinates.json” file will be copied from the top-level project folder into the output folder of the project. Therefore, I add a related entry to the C# project definition file HelloUdf.csproj, as shown below.
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>netcoreapp3.1</TargetFramework>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Microsoft.Spark" Version="0.8.0" />
<Content Include="coordinates.json">
<CopyToOutputDirectory>Always</CopyToOutputDirectory>
</Content>
</ItemGroup>
</Project>
Having completed all the preparation steps, it is now time to perform an initial build of the application via
dotnet build
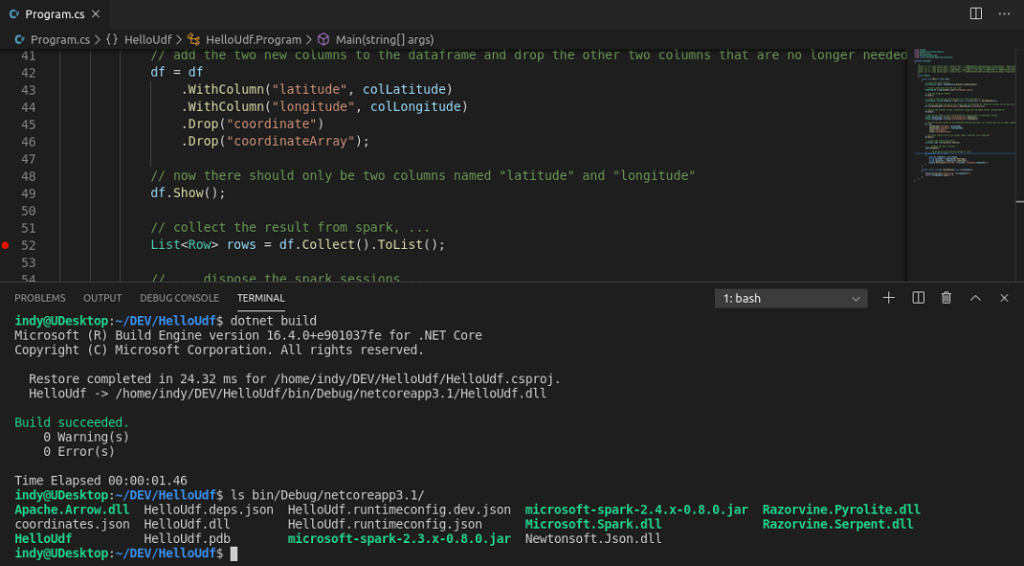
This initial build will create the debug folder (bin/Debug), which we need to map to the dotnet-spark docker container later, so that debugging via the container can actually work.
Running dotnet-spark
Below is the command for running the dotnet-spark container, if you want to debug the user defined function.
docker run -d --name dotnet-spark -p 8080:8080 -p 8081:8081 -p 5567:5567 -p 4040:4040 -v "$HOME/DEV/HelloUdf/bin/Debug:/dotnet/Debug" 3rdman/dotnet-spark:0.8.0
You could skip the mappings for port 8080 (spark-master), 8081 (spark-slave). But what is import is the mapping of the port for the debugging backend (5576) and, as mentioned above, the path to your debug folder.
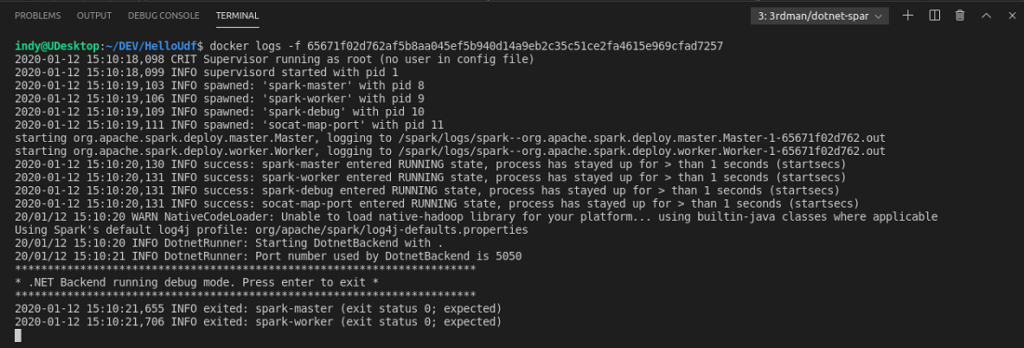
The screenshot below shows the logs of the started container with the .NET Backend running.
Mapping port 4040 might be useful as well, as it allows you to access the Spark UI for more insights on the different jobs and queries. For more details please see my post about .NET for Apache Spark – UDF, VS2019, Docker for Windows
Debugging the first time
As you can get from the screenshot below, I have added a break-point at the following line:
List<Row> rows = df.Collect().ToList();
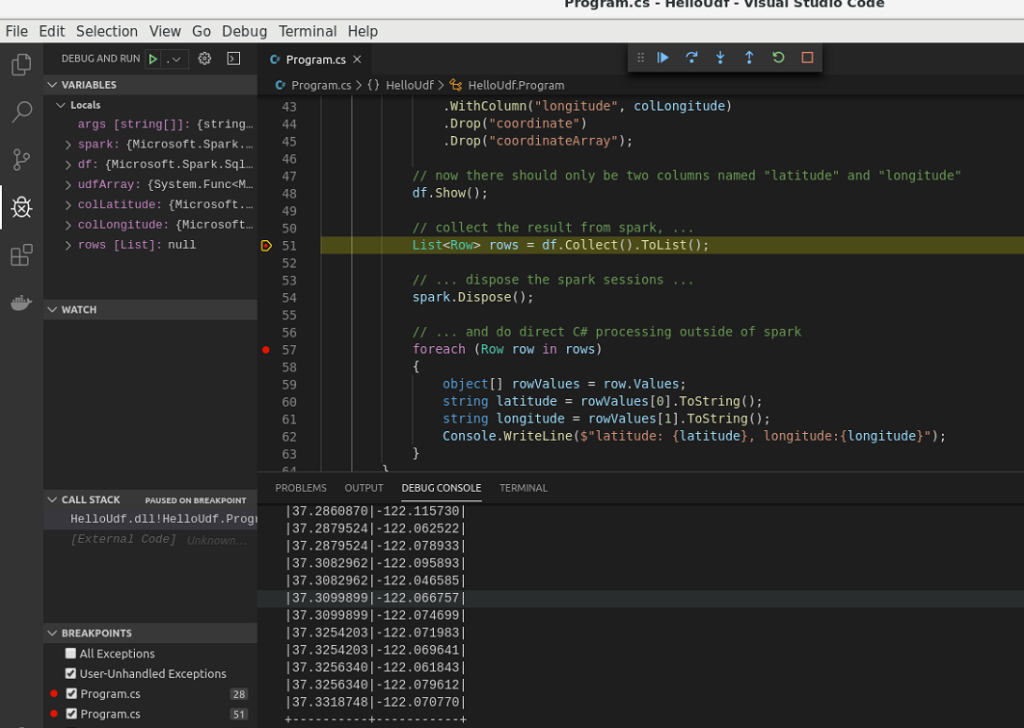
The purpose of this line is to get the data out of spark, back into C#. This is done by collecting all the rows of the spark dataframe and store it in a generic C# list of type Row.
However, executing this line throws an exception.
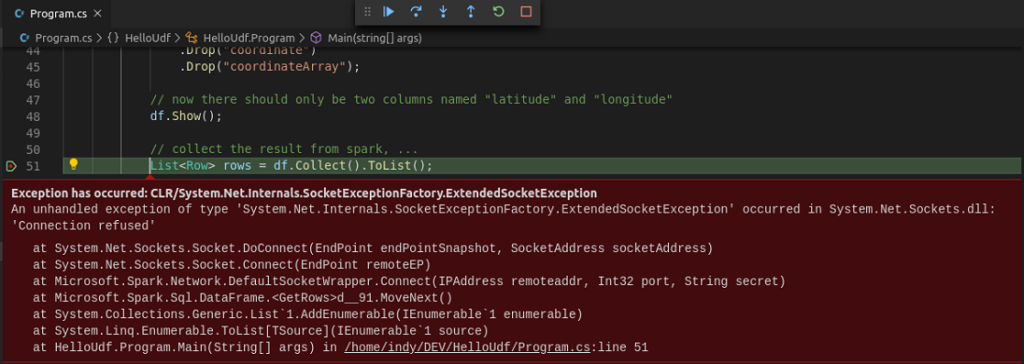
Looking at the “Connection refused” error message, it seems like there is some sort of network issue.
The spark log also shows a SocketTimeoutException.
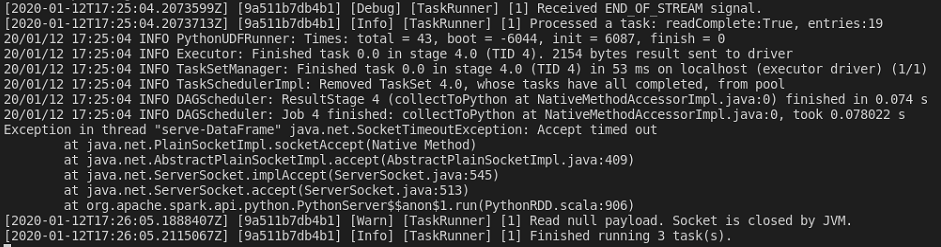
If you have a close look at the logs, you will find that there is a lot of additional ports assigned for the communication with components like the .NET DaemonServer, NettyBlockTransferService and the sparkDriver. All of these ports are assigned dynamically and, because we only have mapped known static ports from our docker container, are not available to Visual Studio Code.
The workaround
Fortunately, if running under Linux, docker provides an option to have all container ports mapped automatically.
As you can see below, I just removed the port mappings and, instead, used –network host
docker run -d --name dotnet-spark --network host -v "$HOME/DEV/HelloUdf/bin/Debug:/dotnet/Debug" 3rdman/dotnet-spark:0.8.0
Starting a new debugging session, the data is now collected without any exception and I can easily iterate over the data rows in C#
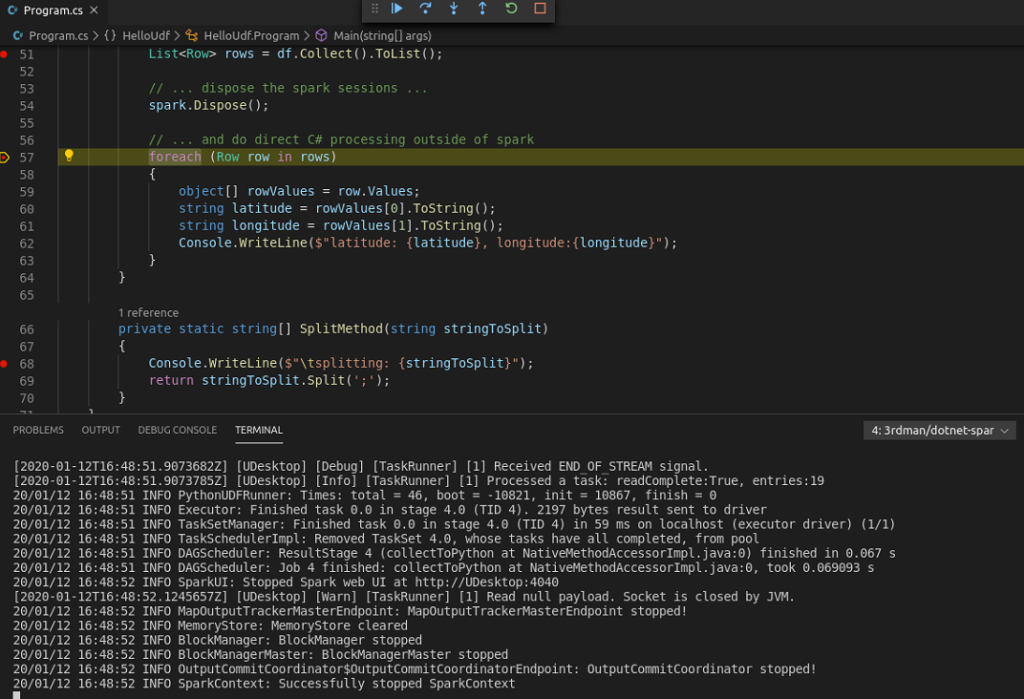
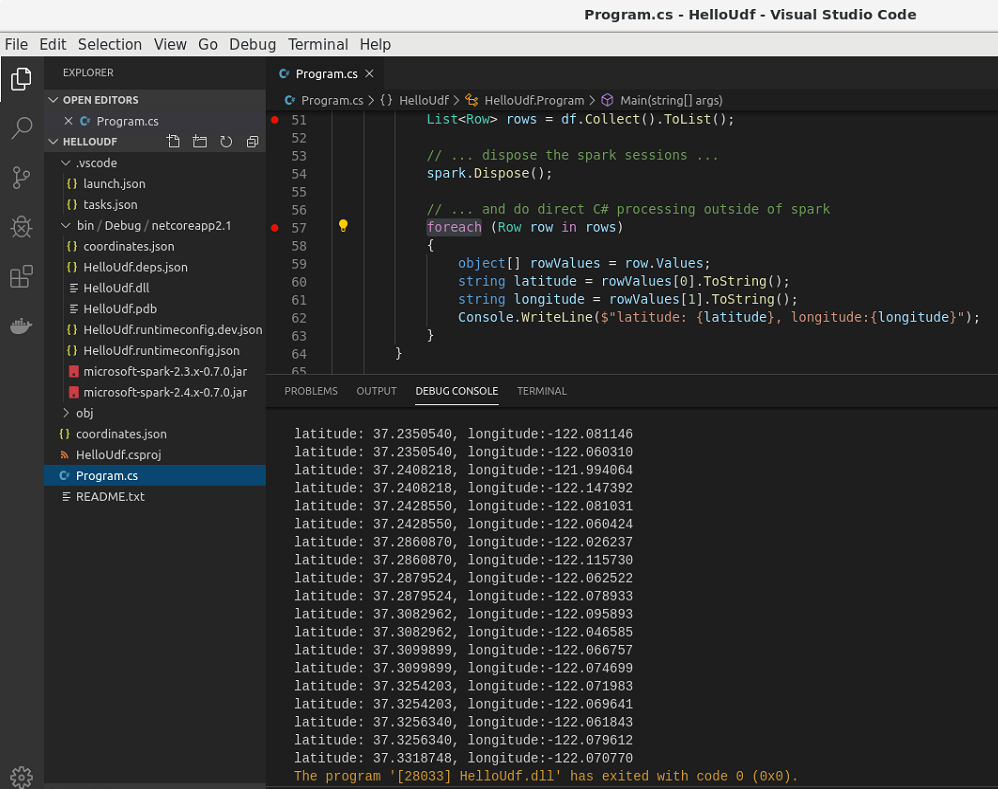
Unfortunately the host network option is not available under windows at the moment. But maybe there will be an option for .NET for Apache Spark in the future, that would allow us to define the port of the related component via an environment variable for example. Just as it is done for the DotnetBackend already. We’ll see.
Thanks a lot for stopping by and have a great time!
19. January 2020
[…] This concludes the first part of exploring .NET for Apache Spark UDF debugging in Visual Studio 2019 under Windows, using my docker image. However, as we will see in the next part, there are still some limitations. One way to overcome these, is to use the docker image on Linux directly, together with Visual Studio Code. So stay tuned for the next part. […]
8. May 2020
[…] .NET for Apache Spark – VSCode with Docker on Linux and df.Collect() […]