

Overview
The latest version of my docker image for .NET for Apache Spark tries to support direct debugging from Visual Studio 2019 and Visual Studio Code.
This is the first article of a small series that will show how this can be done on different environments (Windows and Linux), and what limitations might exist.
Test application & data
I have put together a very simple C# application, named “HelloUdf”, for demonstration purposes. It is supposed to read a JSON file (coordinates.json) that contains one coordinate string per line.
Besides reading the file, the application’s task is to split up the string in each line, utilizing .NET for Apache Spark user define functions, and to store the resulting latitude and longitude values in individual data frame columns.
Here is the content of coordinates.json (Merry Christmas!)
{ "coordinate": "37.2350540;-122.081146" }
{ "coordinate": "37.2350540;-122.060310" }
{ "coordinate": "37.2408218;-121.994064" }
{ "coordinate": "37.2408218;-122.147392" }
{ "coordinate": "37.2428550;-122.081031" }
{ "coordinate": "37.2428550;-122.060424" }
{ "coordinate": "37.2860870;-122.026237" }
{ "coordinate": "37.2860870;-122.115730" }
{ "coordinate": "37.2879524;-122.062522" }
{ "coordinate": "37.2879524;-122.078933" }
{ "coordinate": "37.3082962;-122.095893" }
{ "coordinate": "37.3082962;-122.046585" }
{ "coordinate": "37.3099899;-122.066757" }
{ "coordinate": "37.3099899;-122.074699" }
{ "coordinate": "37.3254203;-122.071983" }
{ "coordinate": "37.3254203;-122.069641" }
{ "coordinate": "37.3256340;-122.061843" }
{ "coordinate": "37.3256340;-122.079612" }
{ "coordinate": "37.3318748;-122.070770" }
And here is the actual C# code of the application:
using System;
using Microsoft.Spark.Sql;
using static Microsoft.Spark.Sql.Functions;
namespace HelloUdf
{
class Program
{
static void Main(string[] args)
{
// create the spark session
var spark = SparkSession.Builder().GetOrCreate();
// create a dataframe from the json file
DataFrame df = spark.Read().Json("coordinates.json");
// show the original content
df.Show(20, 80, false);
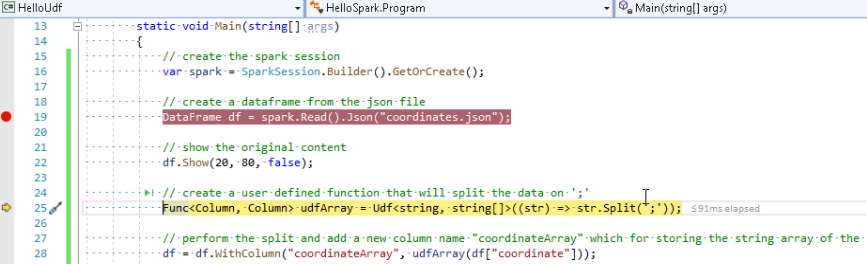
// create a user defined function that will split the data on ';'
Func<Column, Column> udfArray = Udf<string, string[]>((str) => str.Split(';'));
// perform the split and add a new column name "coordinateArray" to store the string array of the split data
df = df.WithColumn("coordinateArray", udfArray(df["coordinate"]));
// display the original column "coordinate" along with the added column "coordinateArray"
df.Show(20, 80, false);
// get the two items of the "coordinateArray" and put them in individual columns
Column colLatitude = df.Col("coordinateArray").GetItem(0);
Column colLongitude = df.Col("coordinateArray").GetItem(1);
// add the two new columns to the dataframe and drop the other two columns that are no longer needed
df = df
.WithColumn("latitude", colLatitude)
.WithColumn("longitude", colLongitude)
.Drop("coordinate")
.Drop("coordinateArray");
// now, there should only be two columns named "latitude" and "longitude"
df.Show(20, 80, false);
}
}
}
Docker for Windows – Linux Container
To check if my application and the UDF is working as expected, I am going to debug the application in multiple test environments. In this part, I start with Visual Studio 2019 and Docker for Windows using Linux Containers.
My solution/project folder is C:\DEV\HelloUdf.
This is important, because I will have to map the debug directory of the project to the /dotnet/Debug directory of the container.
With that in mind, I can create a container from my latest dotnet-spark image, using the following command:
docker run -d --name dotnet-spark -p 8080:8080 -p 8081:8081 -p 5567:5567 -p 4040:4040 -v "C:\DEV\HelloUdf\bin\Debug:/dotnet/Debug" 3rdman/dotnet-spark:latest
Using the Visual Studio Container Tools Extensions , I can check the container logs without leaving Visual Studio.
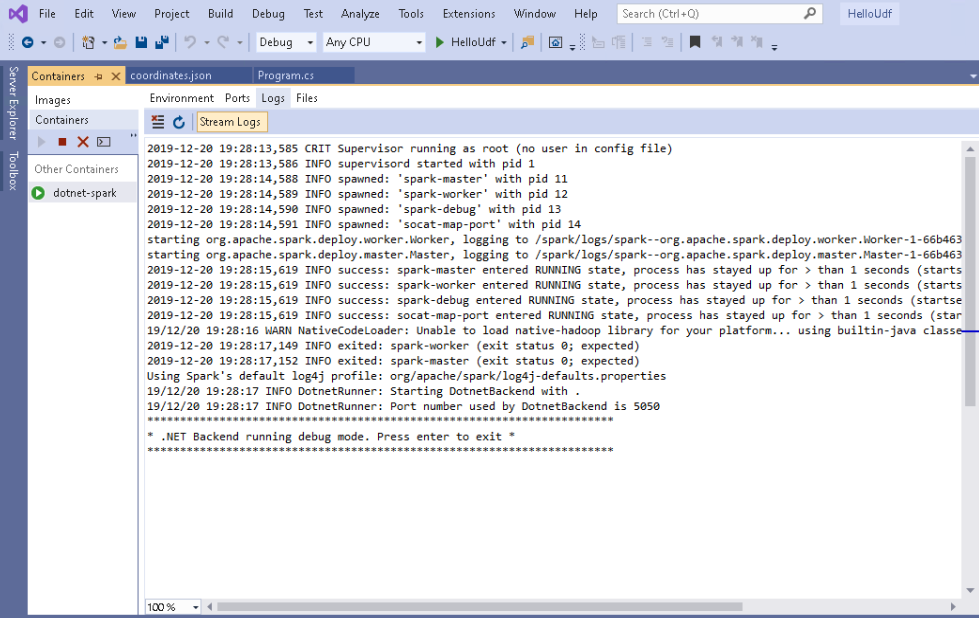
Starting the debug session and reading the JSON file
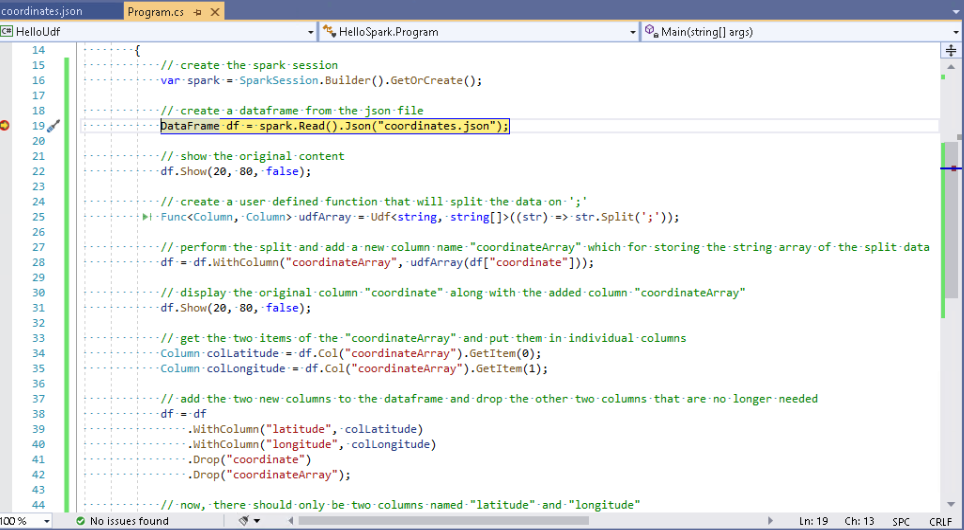
With the .NET Backend up and running in debug mode, I set my first break-point and start the debugging session, pressing F5.
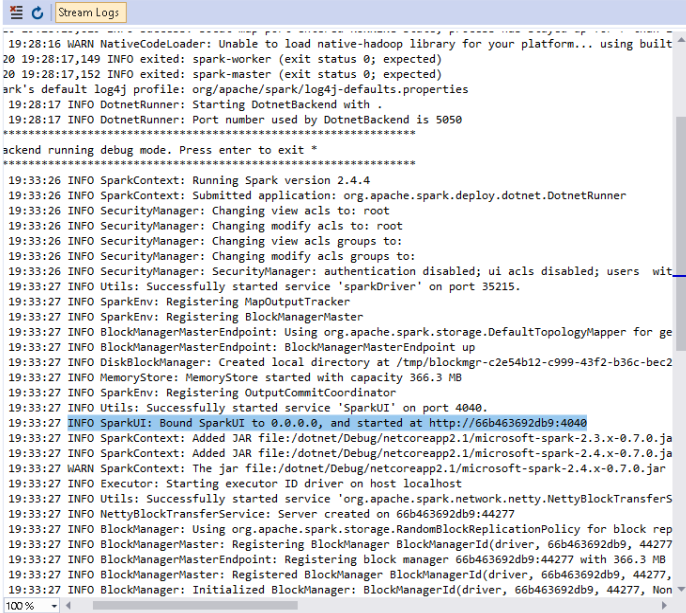
Cross-checking the log, I can see a new spark session created and the SparkUI started on port 4040.
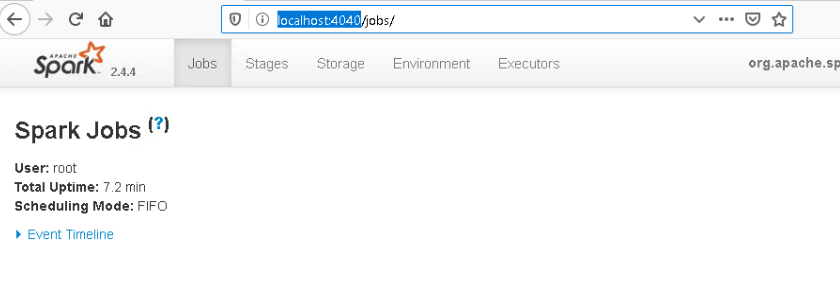
As you will notice, no Spark Jobs have been executed yet. So let’s change that and press F10 once, to execute the following line
DataFrame df = spark.Read().Json("coordinates.json");
More data has been added to the log, which provides some useful information.
- A job with the id 0 has been started and finished.
- Job 0 did read our JSON file
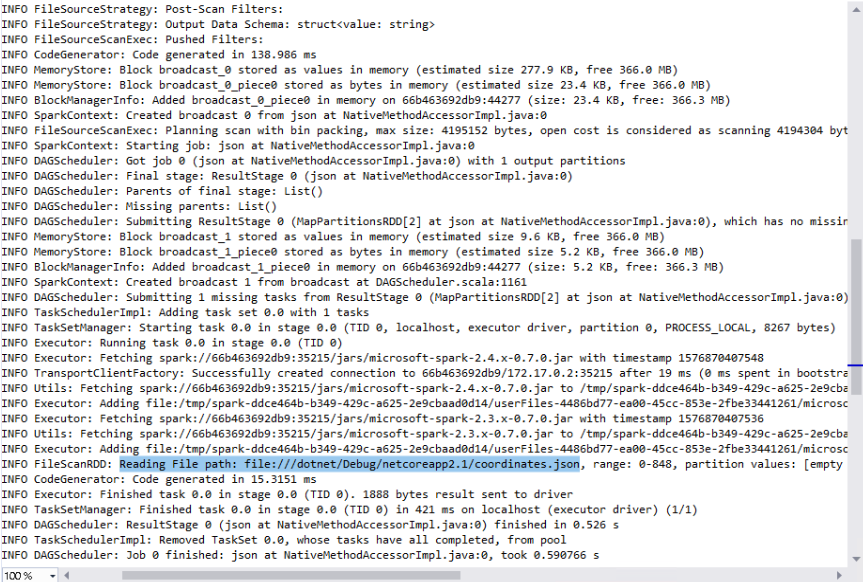
The SparkUI now shows information about Job 0 as well.
Showing the initial data
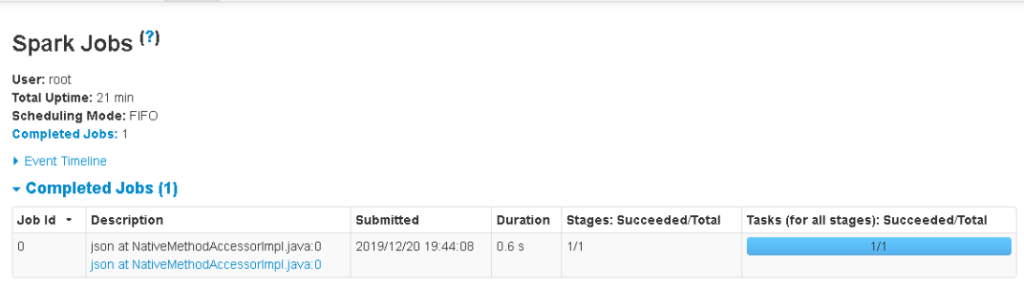
Stepping over the first occurrence of df.Show(), creates Job 1, which is now also listed in the SparkUI
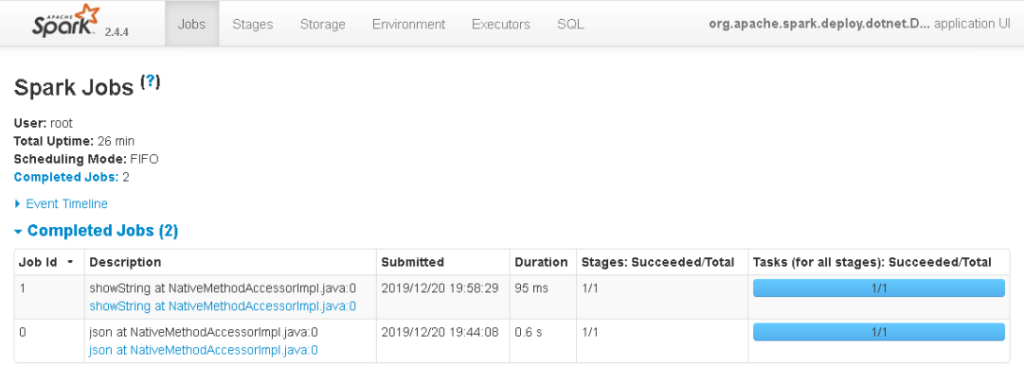
Since job 1 actually needs to query the data to display it, there should also be an entry in the SQL tab of the SparkUI now.
Clicking on the link of the query with Id 0 takes me to the details, as shown below.
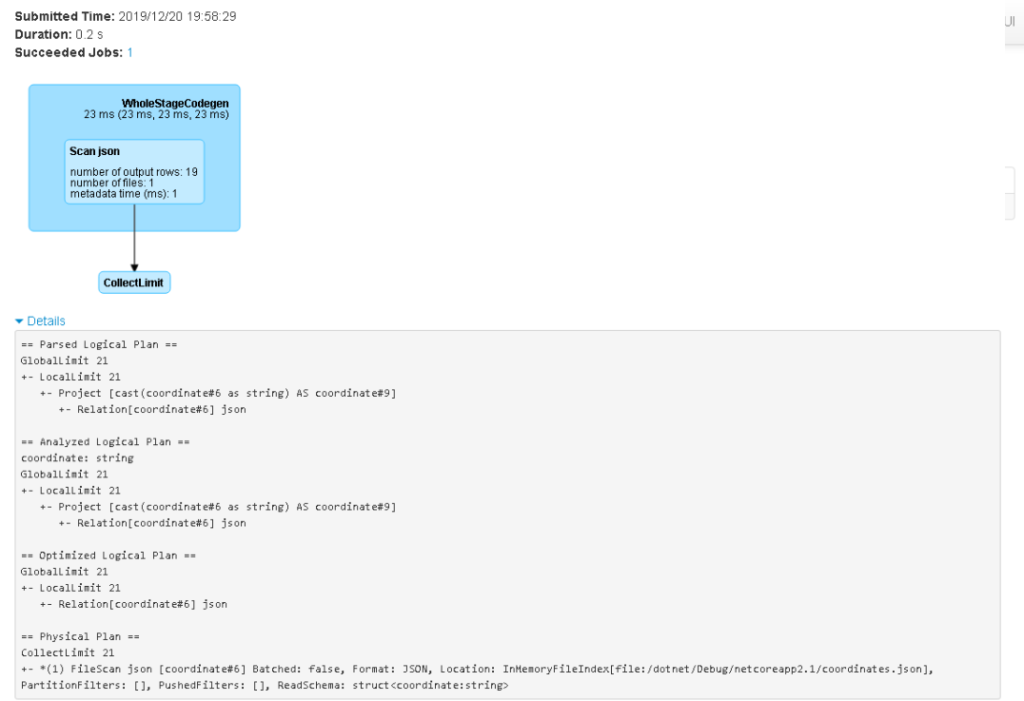
Not very surprisingly, our JSON file has been scanned and the data has been collected up to a certain limit, which was set to 20 rows via the first argument of the Show method.
df.Show(20, 80, false);
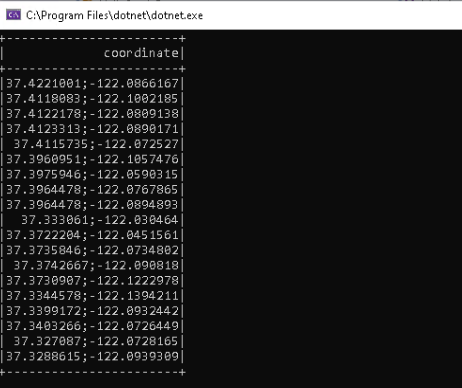
Well, we only got 19 rows in our dataset, so that means that actually all the data should be displayed. A quick look at the console output window reveales, if that is the case.
The user defined function
Creating a user defined function enables us to extend Spark with our own functionality, and .NET for Apache Spark allows us to implement this UDF in C#, for example.
For this simple demo application, I just want to split up the coordinate string into an array of strings, with a semicolon being the separator. I call this user defined function “udfArray”
Func<Column, Column> udfArray = Udf<string, string[]>((str) => str.Split(';'));
As you can see, this Udf method, from the Microsoft.Spark.Sql.Functions namespace, returns a Func that expects one input of type Column and will return a result of type column, as well. The referenced delegate itself expects an input of type string, splits it, and then returns an array of strings.
If the split logic was more complex, I just could have created separate method for it.
private static string[] SplitMethod(string stringToSplit)
{
return stringToSplit.Split(';');
}
Which I then can use as displayed below.
Func<Column, Column> udfArray = Udf<string, string[]>((str) => SplitMethod(str));
Back in our small demo application, the UDF is used like this.
df = df.WithColumn("coordinateArray", udfArray(df["coordinate"]));
This basically takes the dataframe column named “coordinate” and hands it over to the user defined function. The array of strings, that is returned by udfArray, is then stored in a new column named “coordinateArray”.
To validate that, let’s pause after the second occurrence of df.Show.
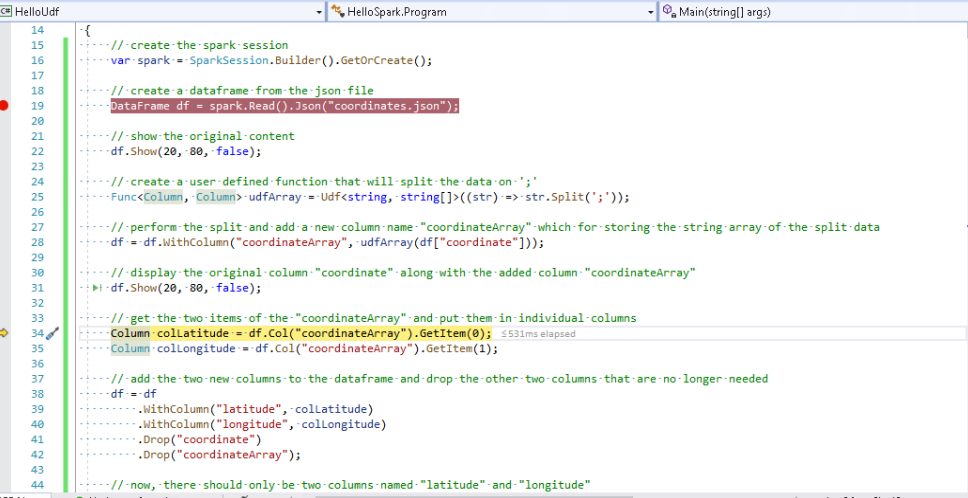
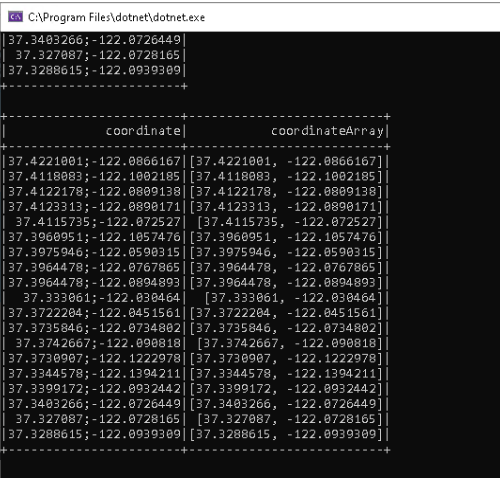
Both columns are now displayed in the console window as expected and SparkUI now also lists a second query with the following details.
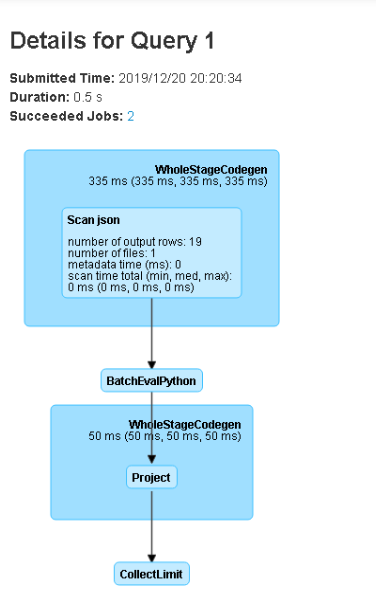
It is interesting to see, that evaluating the user defined function actually seems to involve Python somehow. Time to inspect the log file again, to have a closer look at what is going on.
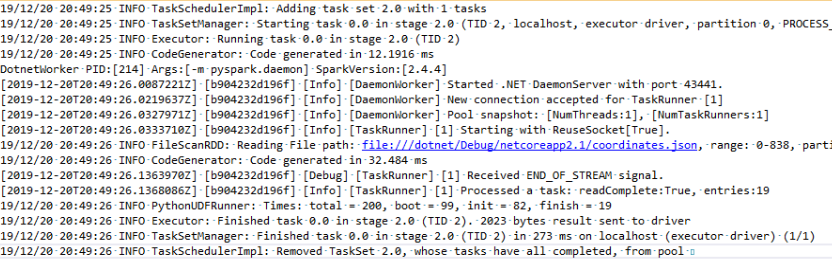
And yes, there are a couple of hints. Especially the line with PythonUDFRunner (4th line from the bottom).
Adding and removing columns
Continuing the debugging session, we now get to the following two lines:
Column colLatitude = df.Col("coordinateArray").GetItem(0);
Column colLongitude = df.Col("coordinateArray").GetItem(1);
As you might have guessed, this gets the first and second item of our string array that is stored in the “coordinateArray” column and assigns it to two newly created variables of type Column. One for the latitude and one for the longitude of the coordinates.
These columns are not yet assigned to our dataframe, however. Let’s do this via the next lines of code.
df = df.WithColumn("latitude", colLatitude)
.WithColumn("longitude", colLongitude)
.Drop("coordinate")
.Drop("coordinateArray");
Besides adding the two new columns, I also drop the original columns “coordinate” and “coordinateArray”.
All that should be displayed now, are the two new columns. So, let’s step over the last occurrence of the df.Show method and inspect the console window.
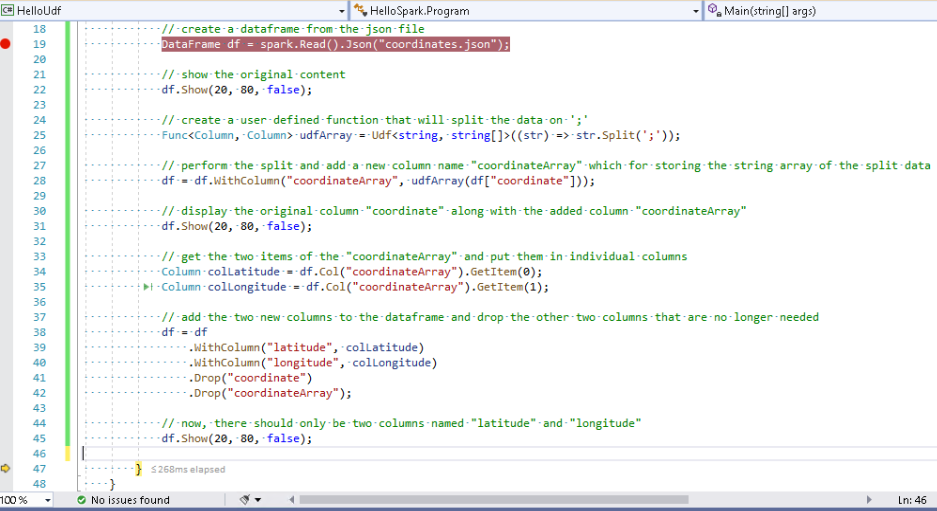
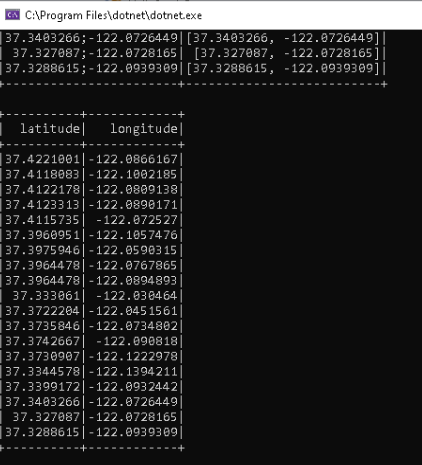
Excellent! The string data has been split and transformed into two individual columns.
This concludes the first part of exploring .NET for Apache Spark UDF debugging in Visual Studio 2019 under Windows, using my docker image. However, as we will see in the next part, there are still some limitations. One way to overcome these, is to use the docker image on Linux directly, together with Visual Studio Code. So stay tuned for the next part.
Merry Christmas
Well, it is the time of the year again and I want to take this opportunity to wish you all a Merry Christmas and a great and relaxing holiday season. See you all again in the next decade!
If you are up for a little challenge, this article contains a small Christmas puzzle somewhere. Can you figure out what it is?
Just post your findings on twitter and feel free to include me via @3rdman4
3. January 2020
[…] last post in 2019 is titled “.NET for Apache Spark – UDF, VS2019, Docker for Windows and a Christmas Puzzle“. As the name implies, it contains a small puzzle related to Christmas. Were you able to find […]
19. January 2020
[…] coordinates.json file is the same as the one that I have used […]