
Version 0.5.0 of .NET for Apache Spark has been released. This means that it is time to update my previously released docker image and also show how to perform a quick test using the included C# example project.
A more detailed description of the image itself is available at https://hub.docker.com/r/3rdman/dotnet-spark
If you are looking for a way to debug your .NET for Apache Spark project, then you might be interested in this post as well.
Starting and accessing the container
You can fire up a container based on this .NET for Apache Spark docker image, using the following command:
docker run -d --name dotnet-spark -e SPARK_WORKER_INSTANCES=2 -p 8080:8080 -p 8081:8081 -p 8082:8082 3rdman/dotnet-spark:0.5.0-linux
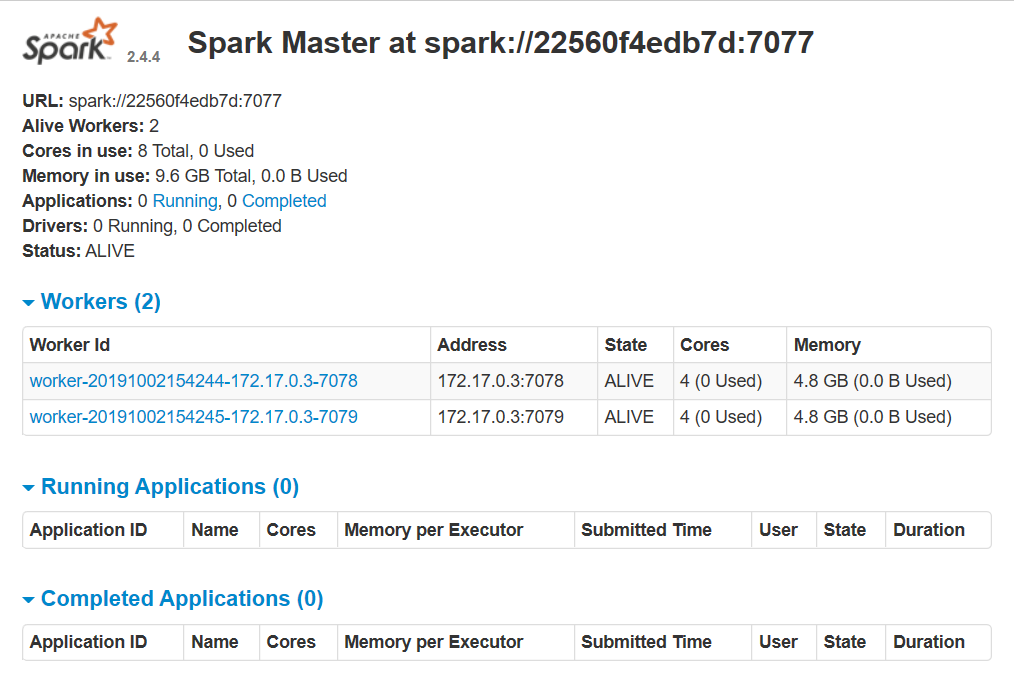
This will start spark, which can be confirmed by pointing your browser to the spark-master Web UI port (8080)
If you want to perform a quick test by running the included example project, just read along.
Building the example
As the screenshot above shows, that we have two worker nodes available waiting for jobs to be executed. So let’s launch as command shell inside the container by using its interactive terminal.
docker exec -it dotnet-spark /bin/bash

This will change your command line prompt to show the id of the docker container.
The docker image also contains a very basic C# example project, named HelloSpark, to demonstrate how you can create a spark job using .NET for Apache Spark. It has been copied over from the getting-started instructions available at https://github.com/dotnet/spark/blob/master/docs/getting-started/ubuntu-instructions.md
Change into the related project folder by using the following command:
cd /dotnet/HelloSpark
Listing the content of that directory (e.g. via ls -la) you should now see that it contains the following 4 files.
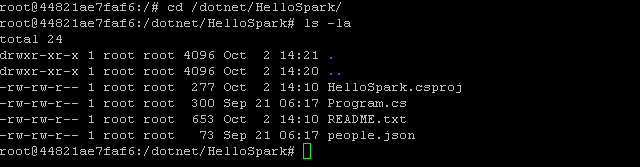
The file named people.json contains the data that we are going to analyze and Program.cs the actual logic written in C#, as shown below.
using Microsoft.Spark.Sql;
namespace HelloSpark
{
class Program
{
static void Main(string[] args)
{
var spark = SparkSession.Builder().GetOrCreate();
var df = spark.Read().Json("people.json");
df.Show();
}
}
}
As you might be able to guess from the source code, HelloSpark doesn’t really do a lot. It reads data from a JSON file (people.json) and then shows its content. Nevertheless, it is quite useful to verify that the fundamental process is working.
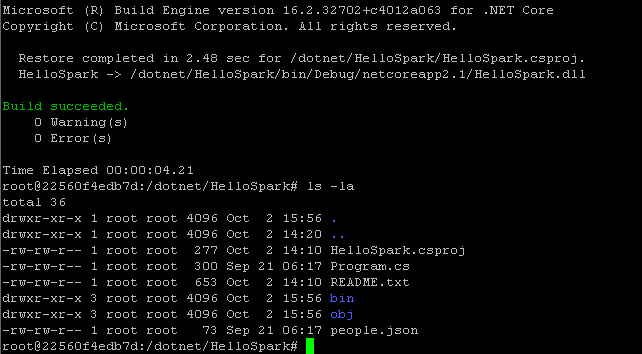
Next, let’s build the .NET C# project. The build process will create a file named HelloSpark.dll, that can be used along with spark-submit and the dotnet runner for spark.
dotnet build
Preparing for execution
Once the build process completed successfully, you should notice two additional directories.
The HelloSpark.dll file mentioned above is located in a sub-directory of the bin folder (Debug/netcoreapp2.1)
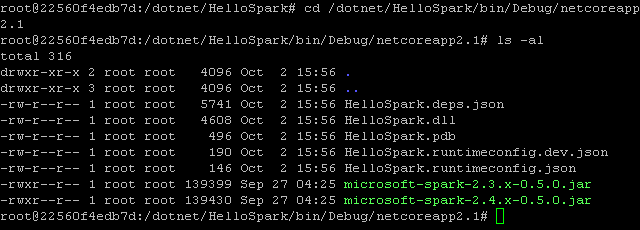
Chaning into this directory using
cd /dotnet/HelloSpark/bin/Debug/netcoreapp2.1
will allow us to simplify/shorten our spark-submit command a bit.
HelloSpark.dll expects our data file named “people.json” in the same directory. Therefore, let’s copy it over from the projects root directory, as the last preparation step.
cp /dotnet/HelloSpark/people.json .
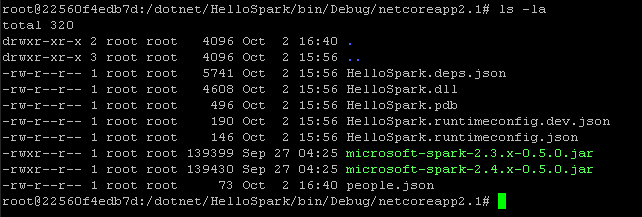
Executing spark-submit
It is finally time to see the HelloSpark example in action.
Running the following command will submit all classes and packages required in order to run HelloSpark as a spark job.
spark-submit --class org.apache.spark.deploy.dotnet.DotnetRunner --master spark://$HOSTNAME:$SPARK_MASTER_PORT microsoft-spark-2.4.x-0.5.0.jar dotnet HelloSpark.dll
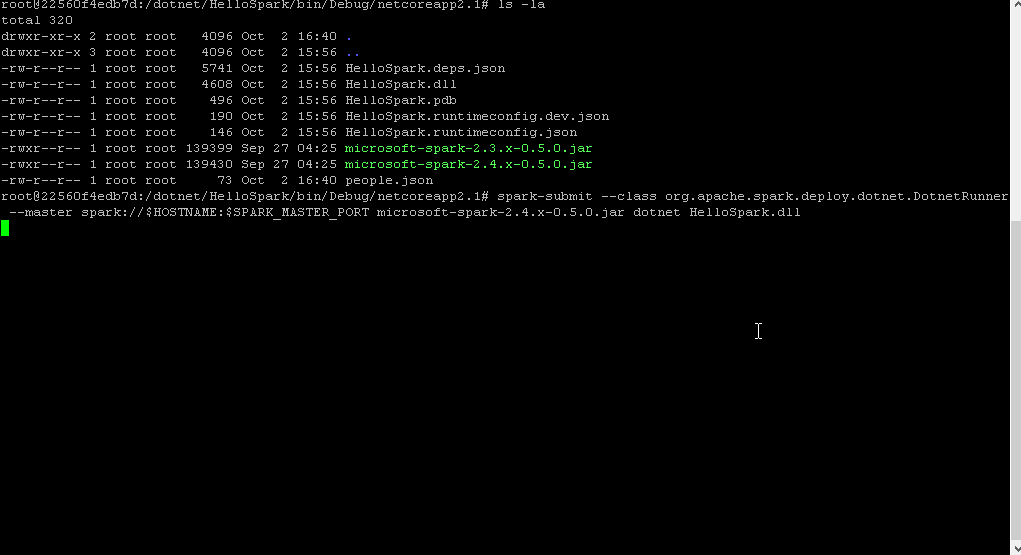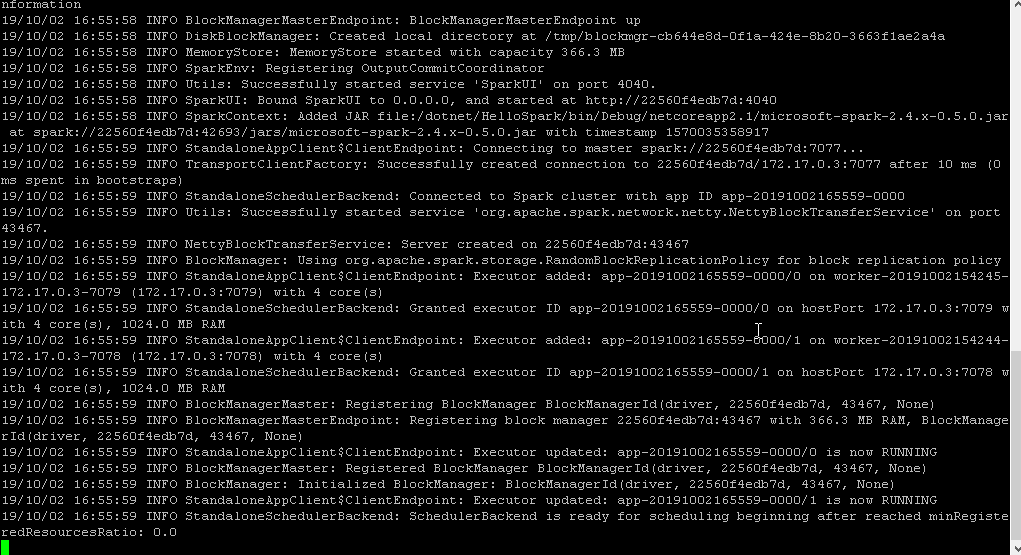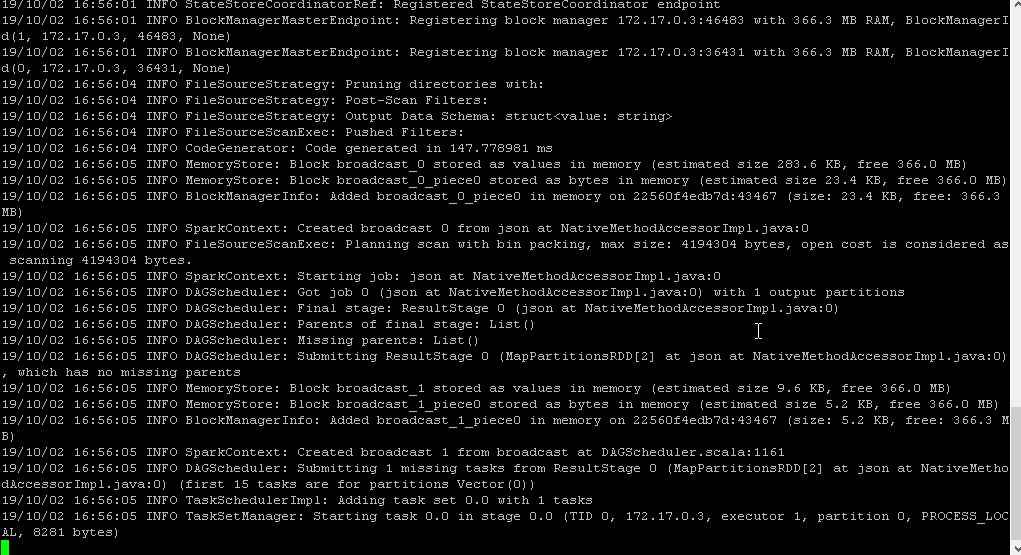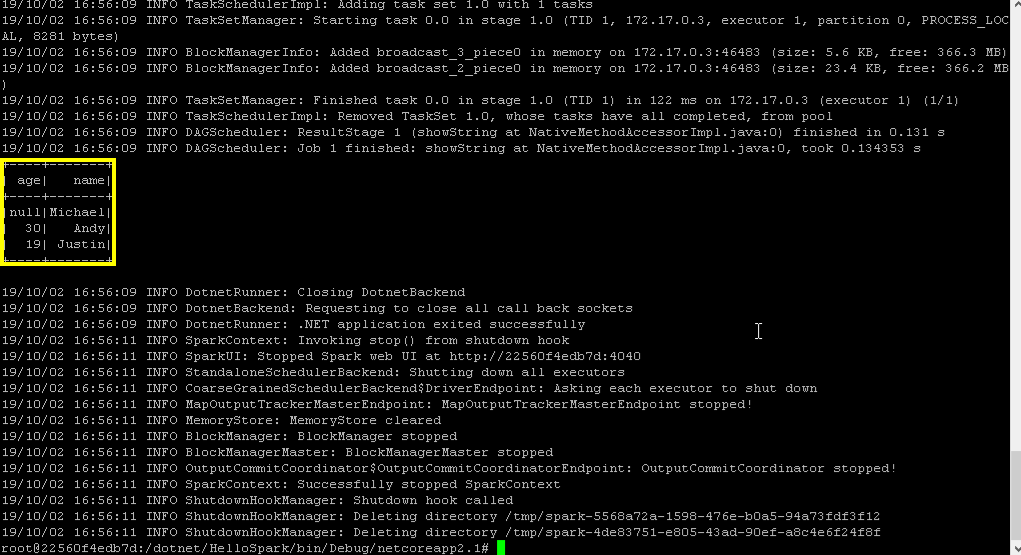
And here we go. After a couple of log messages we actually get the data of or JSON file displayed and can also confirm the successful execution via the Web UI.
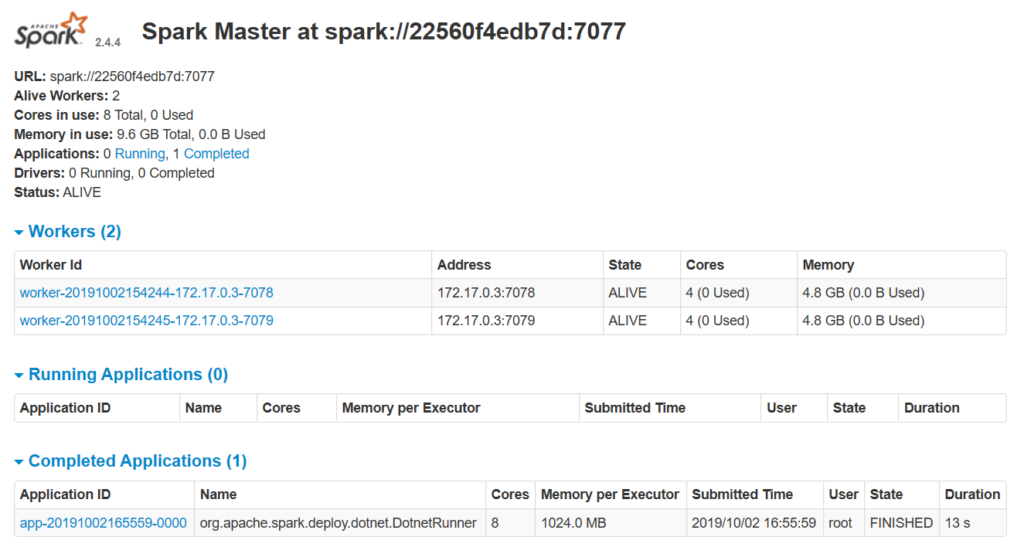
That’s it for now. I hope the updated docker image will encourage you to test out .NET for Apache Spark 0.5.0.
5. October 2019
[…] There’s a new image available. Click here for more details. […]
12. October 2019
[…] I am going to use the HelloSpark example project again, that I’ve already briefly described in this post. […]