
Nachdem ich schon Datentypen/Klassen wie das Array, die LinkedList und ConcurrentQueue etwas näher beleuchtet habe, komme ich nun zum letzten Typen. Einer speziellen C# Implementierung eines Ring-Puffers.
Wer will kann die Problemstellung, den groben Testaufbau und die Auswirkung der verschiedenen Typen gerne nochmal in Teil 1, 2 und 3 nachverfolgen.
Das beste Ergebnis konnte ich bisher mit der ConcurrentQueue erreichen.
Dabei habe ich mit 10 Millionen Einträge vom Typ double, bei einer Frequenz von 2 Millionen neuen Daten pro Sekunde, getestet. Wie sich aber gezeigt hat, scheint der Garbage Collector doch einen nicht zu vernachlässigenden Einfluss auf die Performance zu haben.
Leider konnte ich im .NET Framework bisher “nur” dynamische Implementierungen des Ring-Puffer Konzepts finden und hatte daher darüber nachgedacht, selbst einen Ring-Puffer in C# zu schreiben, wurde dann aber auf GitHub fündig.
Daher möchte ich nun den RingBuffer von Bogdan Radacina vorstellen und testen, wie er im Vergleich zur ConcurrentQueue abschneidet.
Hier also der erste Verglich für insgesamt 10000000 Einträgen, bei 2 Millionen neuen Daten pro Sekunde.
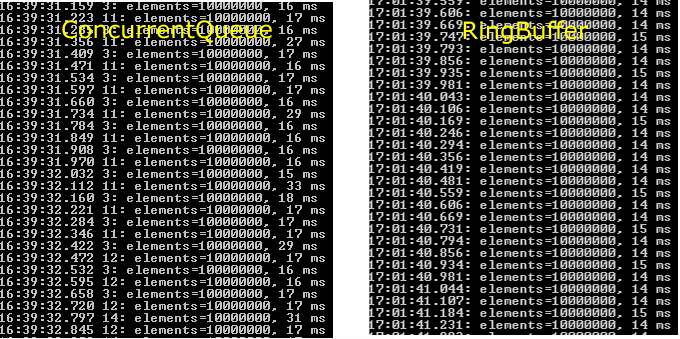
Es ist deutlich zu erkennen, dass es keine Zeitausreißer für die Garbage Collection mehr gibt. Auch die benötigte Zeit für das Hinzufügen der neuen Daten pro Zeitfenster von ca. 50ms, hat sich im ca. 2ms verbessert.
Ein Blick auf die Speicher und CPU-Auslastung bestätigt dies.
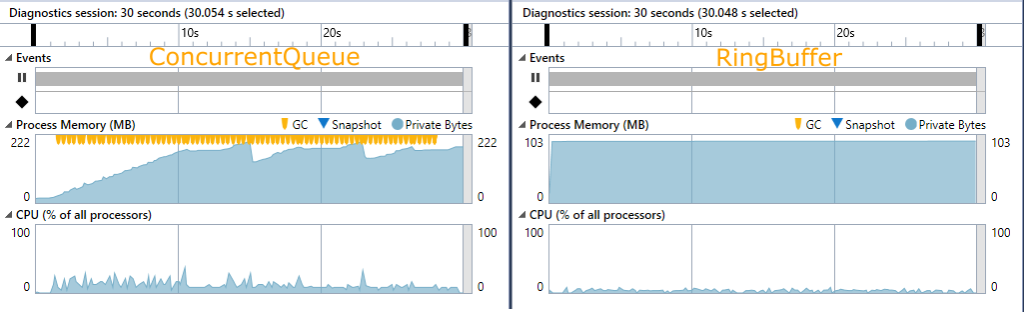
Für die Performanceverbesserung gibt es im Wesentlichen drei Gründe.
- Der benötigte Speicher wird gleich von Anfang an reserviert. Also nicht dynamisch wie bei der LinkedList oder der ConcurrentQueue.
- Der Ringpuffer verwendet nur den bereits reservierten Speicher. Der Speicher der für das gelöschte Element verwendet wurde, wird wieder für das neue Element verwendet. Siehe Eintrag zum Ringpuffer unter https://de.wikipedia.org/wiki/Warteschlange_(Datenstruktur). Dadurch fällt keine Arbeit für den Garbage Collector an.
- Die RingBuffer Implementierung verwendet struct anstelle z.B. eines Arrays. Datentypen die als struct definiert sind, werden nicht als Referenztyp im Heap gespeichert, sondern als Wertetyp direkt im Stack. Es entfällt also der entsprechende Verwaltungsaufwand und das Speichern der Referenz im Stack zu den eigentlichen Daten im Heap. Mehr Details dazu sind z.B. in dem Artikel “Six important .NET concepts: Stack, heap, value types, reference types, boxing, and unboxing” zu finden.
Wie weit lässt sich das Spiel noch treiben?
Es ist interessant zu sehen, wir linear nun die Abhängigkeiten zwischen CPU und der Frequenz für das Hinzufügen neuer Daten auf der einen, und dem Speicher und der Gesamtanzahl der Elemente auf der anderen Seite sind.
Bei 2 Millionen Daten pro Sekunde (100000/50ms) dauerte das Hinzufügen ca. 14ms, bei 150000/50ms ca. 22ms. Beides also ein Faktor von ca. 1,5.

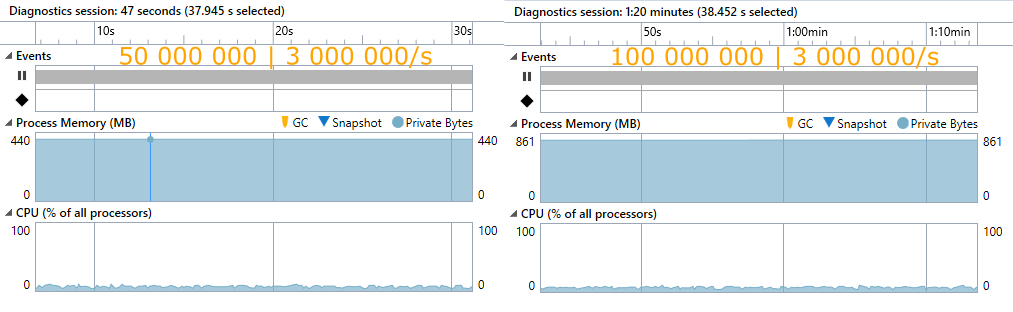
Wurde die Gesamtanzahl von 50 Millionen auf 100 Millionen Daten verdoppelt, so blieb die Zeit für das Hinzufügen von neuen Daten trotzdem gleich. Der Speicherbedarf stieg aber auch hier linear, auf ca. das Doppelte an. Die CPU-Belastung änderte sich nicht.
Bleibt als Résumé:
Die richtige Wahl des Datentypen und das Verständnis der Zusammenhänge sind von entscheidender Bedeutung für die Performance beim Verarbeiten von großen Datenmengen.
Stieß ich beim ersten Test mit insgesamt 10000 Datensätzen und einer Frequenz von 1000 neuen Elementen pro 50ms bereits an die Grenzen, so konnte dies, durch den Einsatz des richtigen Datentyps/Klasse auf insgesamt 100 Millionen Daten (Faktor 10000) und 150000 (Faktor 150) Daten pro 50 Millisekunden gesteigert werden.
Wunderbar!