
Im letzten Teil konnte ich mit Hilfe einer LinkedList bereits eine erhebliche Performanceverbesserung für das zyklische hinzufügen von Daten innerhalb eines fest definierten Zeitraums erzielen.
In diesem Teil will ich herausfinden, ob ich durch die Verwendung einer ConcurrentQueue das Ergebnis noch verbessern kann.
Den letzten Test mit der LinkedList habe ich mit einer Gesamtgröße von 5000000 Einträgen und 50000 neuen Einträgen pro 50 Millisekunden (bzw. 1000000 pro Sekunde) durchgeführt. Daher werde ich die ConcurrentQueue zunächst mit den gleichen Werten testen.
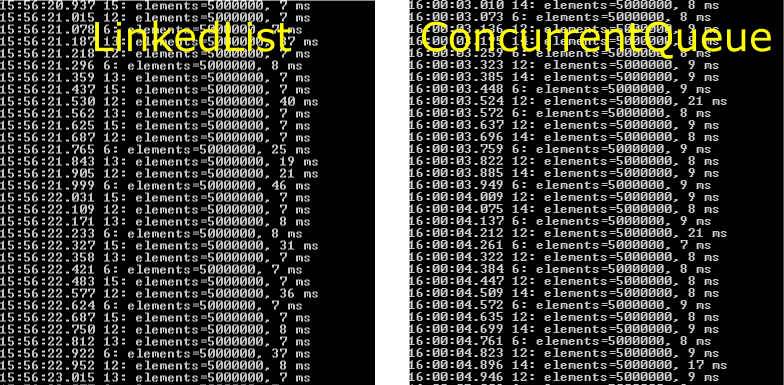
Im Vergleich scheint die ConcurrentQueue keine Verbesserungen zu bringen. Aber der Schein trügt. Werfen wir doch mal einen Blick auf die Speicher und CPU-Auslastung in der Anfangsphase.
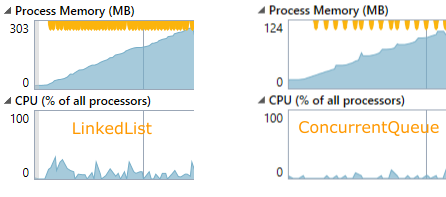
Abgesehen davon, dass man hier gut erkennen kann wie der verwendete Speicher, bei beiden Typen, immer wieder dynamisch erweitert wird, ist ebenso ersichtlich, dass die LinkedList mehr als doppelt so viel RAM benötigt. Auch der Garbage Collector muss viel öfter bemüht werden, was wiederum einen sichtbaren Einfluss auf die Auslastung der CPU hat.
Vergleicht man die Zeiten des Garbage Collectors für beide Typen, so benötigt er bei der ConcurrentQueue nur circa die Hälfte der Zeit.
Nicht zu vernachlässigen ist auch die Tatsache, dass es sich bei der ConcurrentQueue in eine tread-sichere Implementierung handelt.
Mal schauen, wie sich die ConcurrentQueue mit der doppelten Menge an Daten (10 Millionen insgesamt) bei doppelter Frequenz (2 Millionen neue Daten pro Sekunde) schlägt.
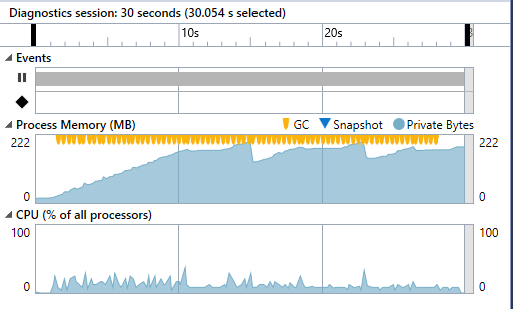
Nicht schlecht, aber das Ende ist in Sicht. Nun wird es Zeit für den letzten Daten-Typen. Einer speziellen, auf Performance ausgelegten Implementierung eines Ringpuffers.