
Auf der Suche nach einem performanten Datentypen für das zyklische Hinzufügen möglichst vieler Datensätze innerhalb eines möglichst kleinen Zeitfensters, hatte ich im ersten Teil ein einfaches Array getestet
Dabei gilt es einen Datentyp zu finden der es erlaubt, einem Pool an Daten mit fester Größe, innerhalb eines Zeitfensters von 50 ms, möglichst viele neue Daten hinzuzufügen.
In der nachfolgenden Animation sind die neue Daten grün, und die zu löschenden Daten rot dargestellt.
Die Größe des Pools ergibt sich aus der Summe des blauen und grünen Bereichs.

Beim gewöhnlichen verwenden des Arrays musste ich intern die Daten von Position i+1 auf Position i kopieren. Das bedeutet viel Arbeit für den Prozessor, weil ja wirklich jeder Speicherplatz des Arrays neu beschrieben wird.
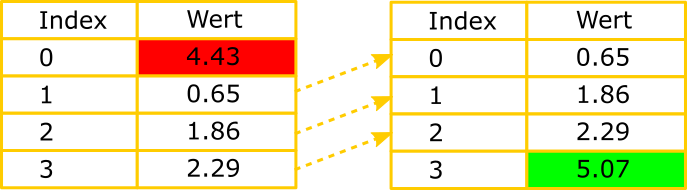
Viel schöner wäre es, wenn alle Daten im Speicher an ihrem Platz bleiben, und das älteste Element einfach durch das neueste ersetzt werden könnte.
Ein extrem flexibler Datentyp, der dies und noch viel mehr erlaubt, ist die LinkedList.
Eine LinkedList ist zweifach verlinkt. Einmal mit dem vorherigen Element und einmal mit dem nachfolgenden (falls vorhanden). Dadurch kann der allergrößte Teil der Daten einfach am gleichen Speicherplatz verweilen. Nur das Löschen und Hinzufügen verursacht Last.
Das Schaubild unten verdeutlicht die prinzipielle Funktionsweise der LinkedList. Zu jedem Wert wird eine Referenz auf die Vorgänger- und Nachfolger-Adresse gespeichert. Der erste Wert hat dabei keinen Vorgänger und der letzte, keinen Nachfolger.
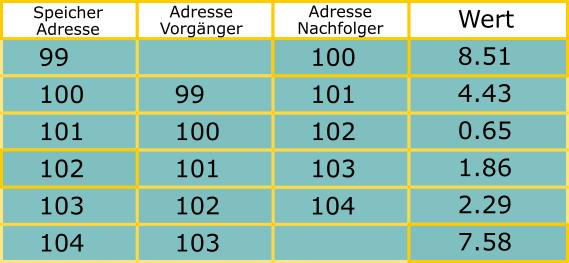
Wir ein Datensatz gelöscht (rot), so müssen intern einfach nur die Referenzen angepasst werden (gelb). Ebenso beim Hinzufügen (grün). Die Mehrheit der Datensätze muss nicht angefasst werden (blau).

Nun wird es Zeit die Performance der LinkedList mit der des gewöhnlichen und zugegebenermaßen nicht besonders schlau genutzten Arrays zu vergleichen. Übrigens: Eine LinkedList ist für das Schreiben nicht thread safe. Man muss sich also selber um das Locken kümmern.
Ich starte den Test wieder mit einer Gesamtanzahl von 10000 Listeneinträgen und 1000 neuen Datensätzen pro 50 ms.
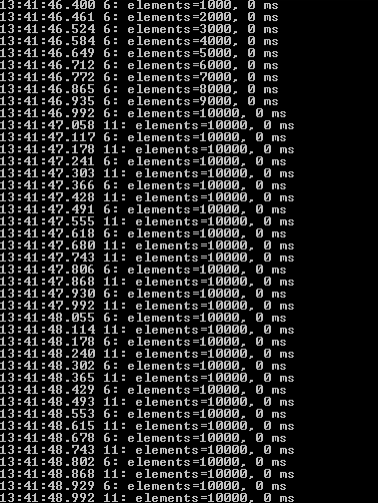

Wie erwartet wird, wegen der Speicherung der Referenzen zu den verlinkten Elementen, etwas mehr Speicher benötigt als für das Array.
Allerdings hat sich die Performance im Vergleich dazu wesentlich verbessert
Nun erhöhe ich die Gesamtanzahl um den Faktor 100 (also auf 1000000) und die Anzahl der neuen Einträge pro 50ms auf 10000 (also 200kHz)
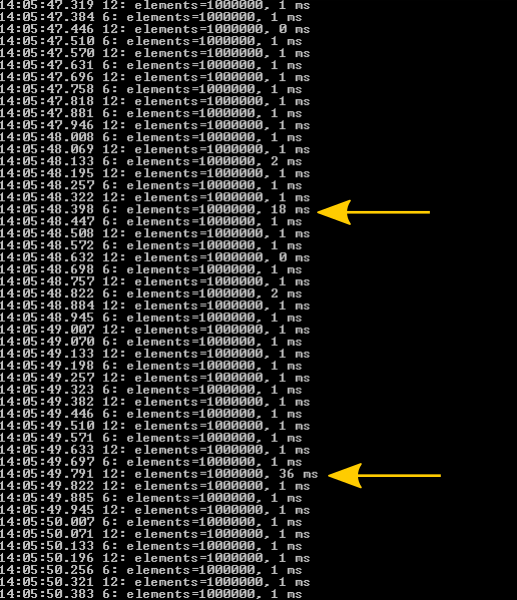
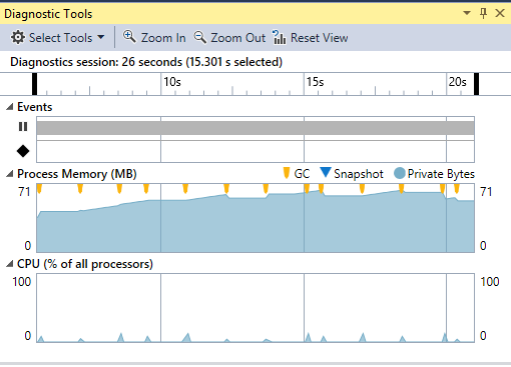
Das Ergebnis kann sich immer noch sehen lassen. Interessanterweise scheint sich aber der Garbage Collector nun als limitierender Faktor anzukündigen. Beim Freigeben des nicht mehr verwendeten Speichers wird einiges an CPU Ressourcen benötigt.
Erhöhe ich die Frequenz der neu hinzu kommenden Daten und der Gesamtanzahl nochmal um den Faktor 5, dann wird das Problem noch deutlicher.
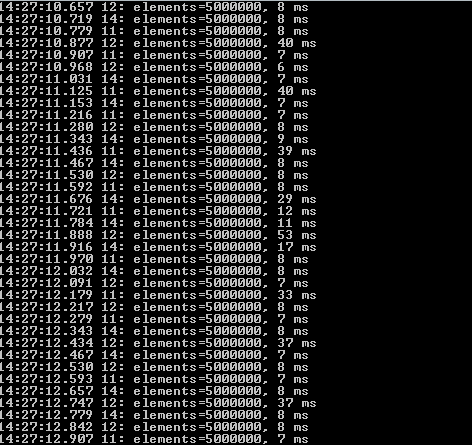
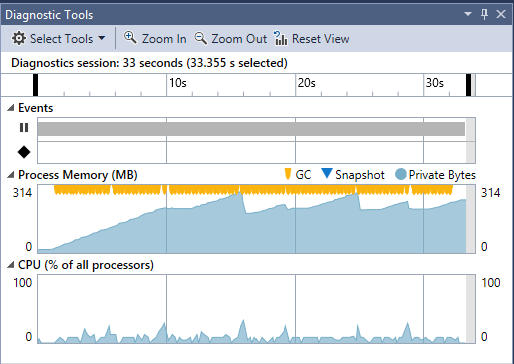
Zwar erhöht sich die Zeitspanne die benötigt wird um die neuen Daten hinzuzufügen, der Garbage Collector wird aber eindeutig zum limitierenden Faktor.
Im nächsten Teil werde ich einen Datentyp testen, der mich meinem Ziel noch etwas näher bringt. Der ConcurrentQueue.