
Im ersten Teil habe ich beschrieben, wie ich das Docker Image von Apache Zeppelin um die Spark Version 2.4.0 erweitert und kurz getestet habe.
In diesem Teil werde ich einen eigenen Interpreter für PostgreSQL hinzufügen und eine erste Abfrage durchführen, um diesen zu testen. Danach wird noch die Konfiguration für den Spark Interpreter angepasst, damit dieser auch mit PostgreSQL arbeiten kann.
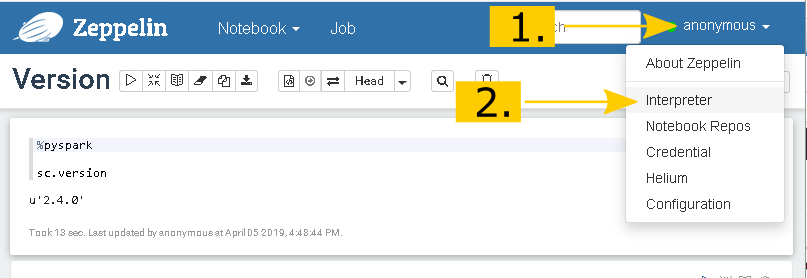
Um den neuen Interpreter hinzuzufügen, klicke ich auf das Drop-Down Menü, rechts im Zeppelin Header und wähle den Punkt Interpreter aus
Mit Create wird die Seite zum Konfigurieren des neuen Interpreters geladen und unter Interpreter … more